La batalla de los embeddings: cuando tres modelos de IA compiten por entender el español gubernamental
Un análisis comparativo entre tres modelos de embeddings (Nomic Embed, Gemini, Jina) evaluando velocidad, calidad y estabilidad en búsqueda vectorial para documentos oficiales mexicanos.

Cuando los algoritmos se enfrentan al lenguaje burocrático mexicano
En el mundo de la inteligencia artificial, uno de los análisis más importantes en el ámbito de procesamiento de lenguaje natural es evaluar cómo diferentes modelos de embeddings comprenden y representan el complejo universo del lenguaje gubernamental mexicano. En este estudio analizamos tres modelos de embeddings: Nomic Embed (modelo local), Gemini (API de Google), y Jina (especializado en búsqueda vectorial). Su objetivo: descifrar, entender y hacer búsquedas efectivas en miles de documentos del Diario Oficial de la Federación.
Los resultados revelan diferencias significativas entre velocidad, precisión y las ventajas operacionales de soluciones locales versus APIs en la nube.
Hallazgos principales del análisis
Principales conclusiones del estudio:
- Gemini ofrece la calidad superior de respuestas, seguido por Jina con calidad equivalente pero perspectiva diferente, y Nomic Embed con calidad funcional
- Las métricas de similitud presentan diferencias de rendimiento prácticamente despreciables (~2ms)
- Nomic Embed lidera en rendimiento operacional y estabilidad, pero requiere datos muy limpios, mientras que Gemini y Jina son robustos ante datos de calidad variable
- Ambas métricas recuperan contenido idéntico, diferenciándose únicamente en la escala de puntuación de relevancia
- La decisión de modelo debe priorizar calidad de respuestas vs autonomía operacional según las necesidades específicas del negocio
El desafío: análisis de búsqueda vectorial en documentos gubernamentales
Cuando construimos sistemas de Recuperación Aumentada por Generación (RAG) como DOF-RAG, nos enfrentamos a un problema que va mucho más allá de la búsqueda tradicional de palabras clave. Los ciudadanos no buscan exactamente las mismas palabras que aparecen en los documentos oficiales. Alguien podría preguntar “¿Cómo me afilio al IMSS-Bienestar?” mientras que el documento oficial habla de “procedimientos de incorporación al régimen de seguridad social”.
Aquí es donde entran los embeddings vectoriales: representaciones matemáticas que capturan el significado semántico del texto, permitiendo que el sistema entienda que ambas frases se refieren al mismo concepto, aunque usen palabras completamente diferentes.
Este análisis se basa en 42 consultas representativas procesadas sobre más de 5,000 fragmentos de documentos del DOF, evaluando tanto velocidad de búsqueda como calidad de respuestas mediante métodos nativos de DuckDB.
Pero surge la pregunta clave: ¿qué modelo de embeddings funciona mejor para documentos gubernamentales mexicanos? Y más importante aún: ¿importa realmente si usamos distancia euclidiana (L2) o similitud coseno?
Los modelos evaluados: características y especificaciones técnicas
🏠 Nomic Embed: Modelo local
Características técnicas: Un modelo completamente local (modernbert-embed-base) que opera sin dependencias de internet.
Especificaciones:
- Dimensiones: 768 (arquitectura compacta y eficiente)
- Tamaño: ~596 MB (factible para hardware estándar)
- Ventaja principal: Latencia de red nula
- Perfil operacional: Modelo confiable para entornos con requisitos de disponibilidad constante
Justificación de selección: Representa la independencia operacional total. En escenarios donde la conectividad es limitada, las APIs no están disponibles, o existen restricciones presupuestarias, Nomic Embed mantiene funcionalidad completa.
🌟 Gemini: API comercial de Google
Características técnicas: Modelo de embeddings de Google con infraestructura cloud empresarial.
Especificaciones:
- Dimensiones: 1536 (alta dimensionalidad para representación semántica compleja)
- Velocidad: 3-5 segundos por consulta
- Calidad: Comprensión contextual avanzada
- Limitaciones: 15 peticiones por minuto, 1000 peticiones por día (plan gratuito)
Justificación de selección: Gemini representa el estado actual de embeddings comerciales, combinando calidad semántica superior con la estabilidad y confiabilidad de la infraestructura de Google.
Consideraciones del plan gratuito: Al utilizar el tier gratuito de Gemini, estamos sujetos a limitaciones de 15 peticiones por minuto y 1000 peticiones diarias.
🎯 Jina: API especializada en embeddings
Características técnicas: Empresa especializada exclusivamente en embeddings y búsqueda vectorial.
Especificaciones:
- Dimensiones: 1024 (dimensionalidad intermedia)
- Especialización: Optimización específica para búsqueda vectorial
- Plan: Gratuito con 10 millones de tokens disponibles
- Perfil operacional: Modelo especializado con rendimiento variable según disponibilidad del servicio
Justificación de selección: Jina ofrece una perspectiva especializada en el ecosistema de embeddings, proporcionando un punto de comparación valioso entre soluciones locales y APIs comerciales de propósito general.
Limitaciones del plan gratuito: Jina ofrece 10 millones de tokens para procesar, pero al ser un plan experimental, las peticiones se procesan con baja prioridad, resultando en tiempos de respuesta variables.
Consideraciones de servicios en la nube
Tanto Gemini como Jina operan bajo planes gratuitos, lo que introduce algunas limitaciones operacionales importantes que explican parte de la variabilidad observada en los resultados, especialmente para Jina que mostró tiempos de respuesta de 30-50 segundos promedio.
Esta realidad hace que Nomic Embed, pese a su menor calidad semántica, ofrezca ventajas significativas de autonomía y predictibilidad operacional.
Metodología de evaluación: métodos nativos de DuckDB
Para garantizar una comparación equitativa entre modelos, utilizamos los métodos nativos de DuckDB - funciones optimizadas (array_cosine_similarity() y array_distance()) que son 35-50 veces más rápidas que las implementaciones manuales en Python.
Impacto en rendimiento: La diferencia práctica es sustancial: pasar de búsquedas que requerían 500-800ms a búsquedas optimizadas de 9-16ms. Esta mejora es comparable a la diferencia entre procesar datos manualmente versus utilizar algoritmos altamente optimizados.
L2 vs Coseno: la eterna pregunta
Distancia L2 (Euclidiana): Mide qué tan “lejos” están dos vectores en el espacio matemático. Como medir la distancia entre dos puntos en un mapa.
Similitud Coseno: Mide qué tan “alineados” están dos vectores, ignorando su magnitud. Como medir si dos flechas apuntan en la misma dirección, sin importar su tamaño.
La pregunta que todos se hacen: ¿importa cuál usar? Spoiler: menos de lo que pensarías.
Los resultados: cuando los números hablan por sí solos
Análisis 1: Velocidad de búsqueda vectorial
| Modelo | L2 (ms) | Coseno (ms) | Diferencia | Observación |
|---|---|---|---|---|
| Nomic Embed | 14.03 | 12.62 | +1.41ms | Coseno ligeramente más rápido |
| Gemini | 16.20 | 14.12 | +2.08ms | Coseno ligeramente más rápido |
| Jina | 11.69 | 9.21 | +2.48ms | Coseno ligeramente más rápido |
Hallazgo importante: La diferencia promedio de ~2ms entre L2 y Coseno es prácticamente despreciable para aplicaciones en producción. Esta diferencia es comparable a debatir si una tarea se completa en 4.012 segundos versus 4.014 segundos: técnicamente medible, prácticamente irrelevante.
Análisis 2: Rendimiento total (embedding + búsqueda)
Este análisis examina no solo la velocidad de búsqueda, sino también la velocidad de procesamiento para generar embeddings de nuevas consultas.
Métrica L2
| Posición | Modelo | Tiempo Total | Consultas/seg | Chunks/seg |
|---|---|---|---|---|
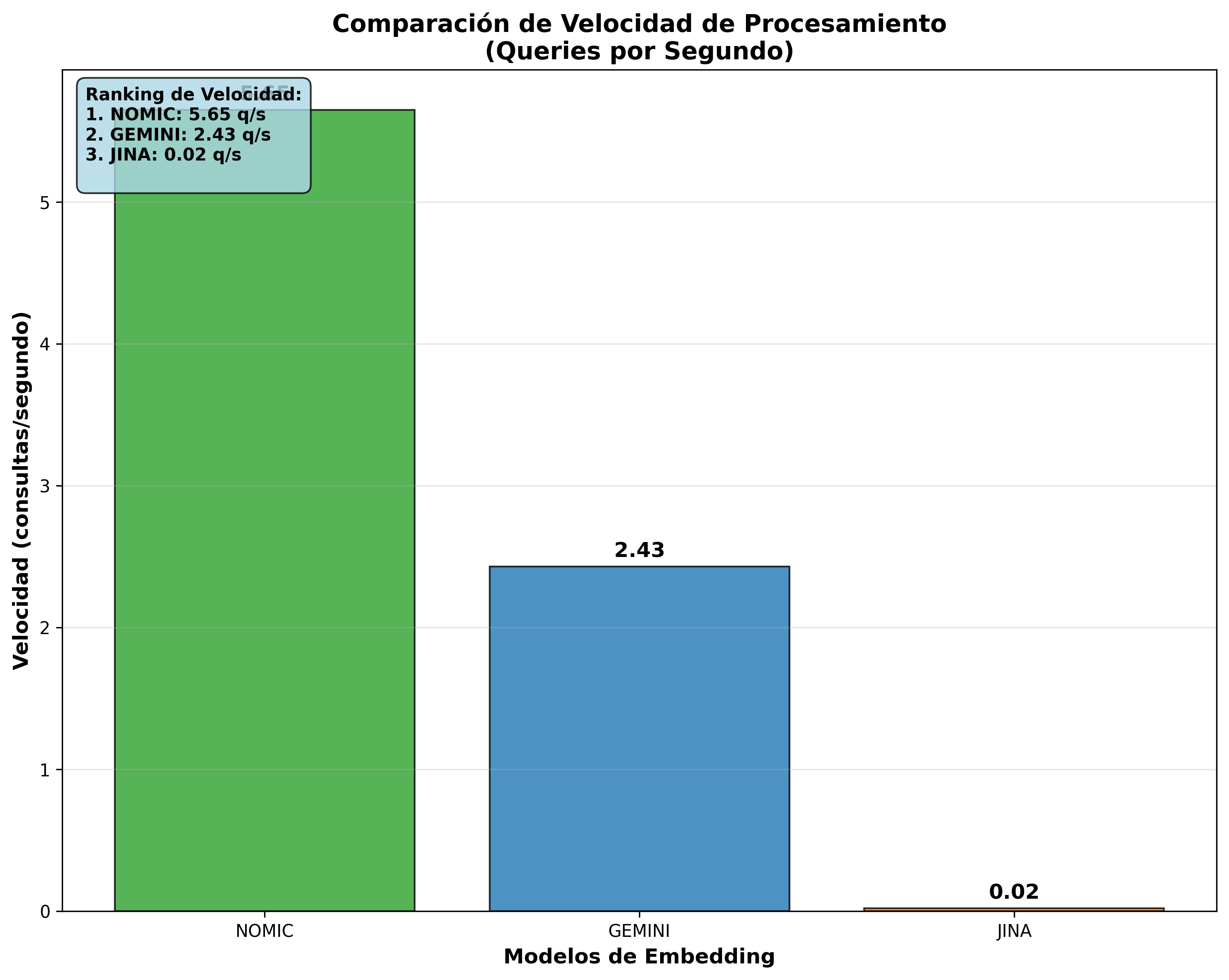
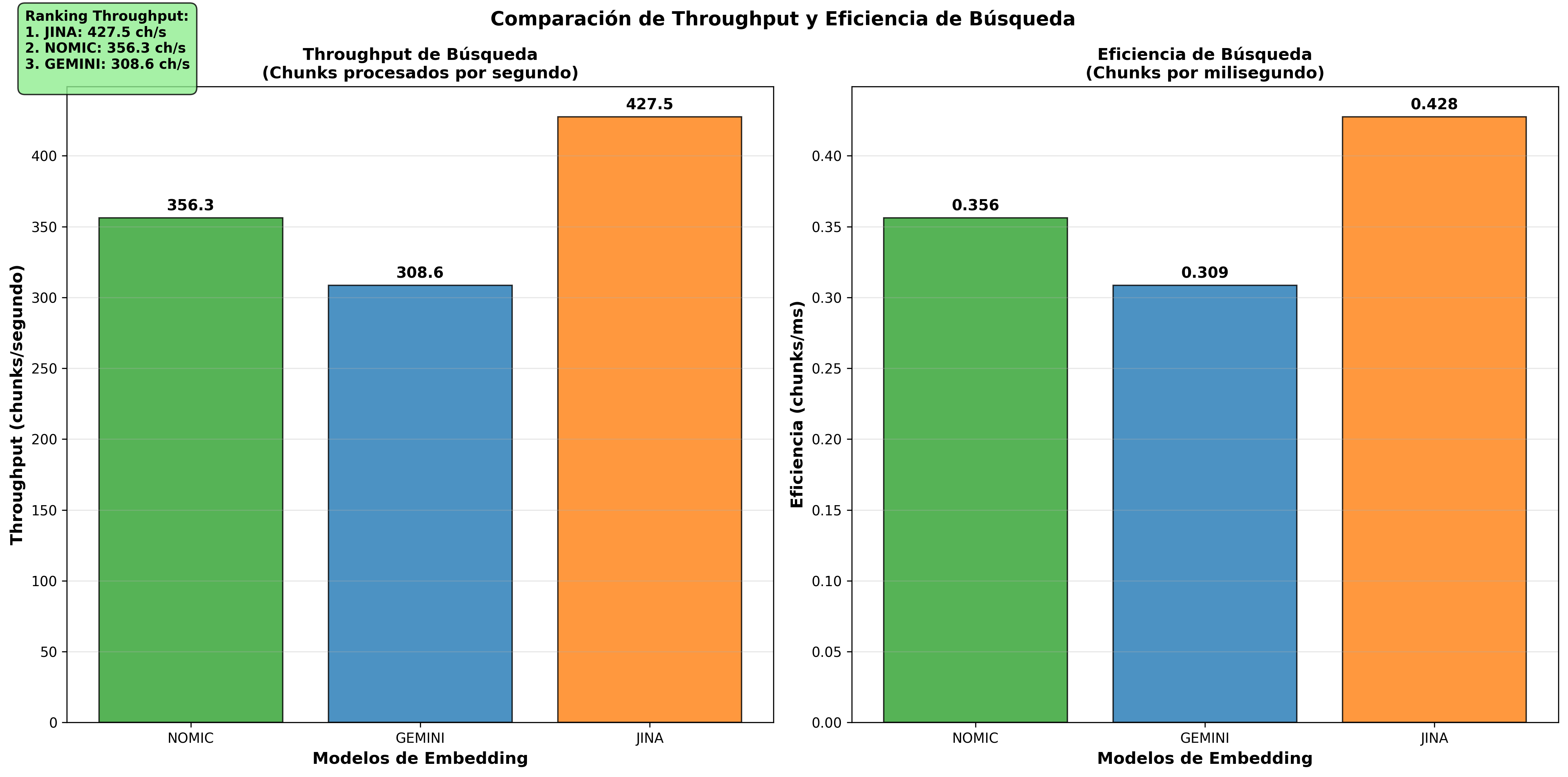
| 1° | Nomic Embed | 177ms | 5.65 | 356.3 |
| 2° | Gemini | 412ms | 2.43 | 308.6 |
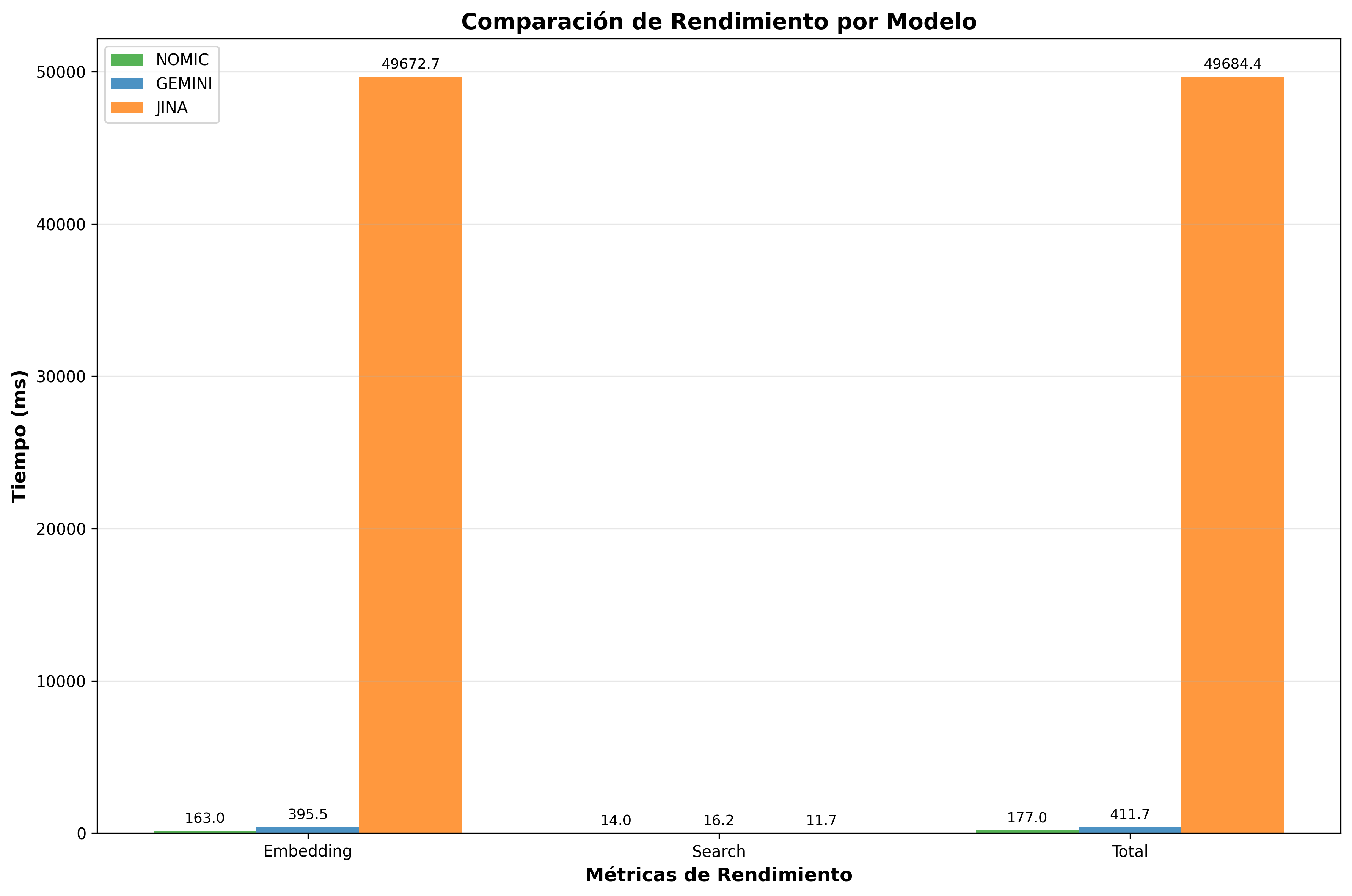
| 3° | Jina | 49,684ms | 0.02 | 427.5 |
Métrica Coseno
| Posición | Modelo | Tiempo Total | Consultas/seg | Chunks/seg |
|---|---|---|---|---|
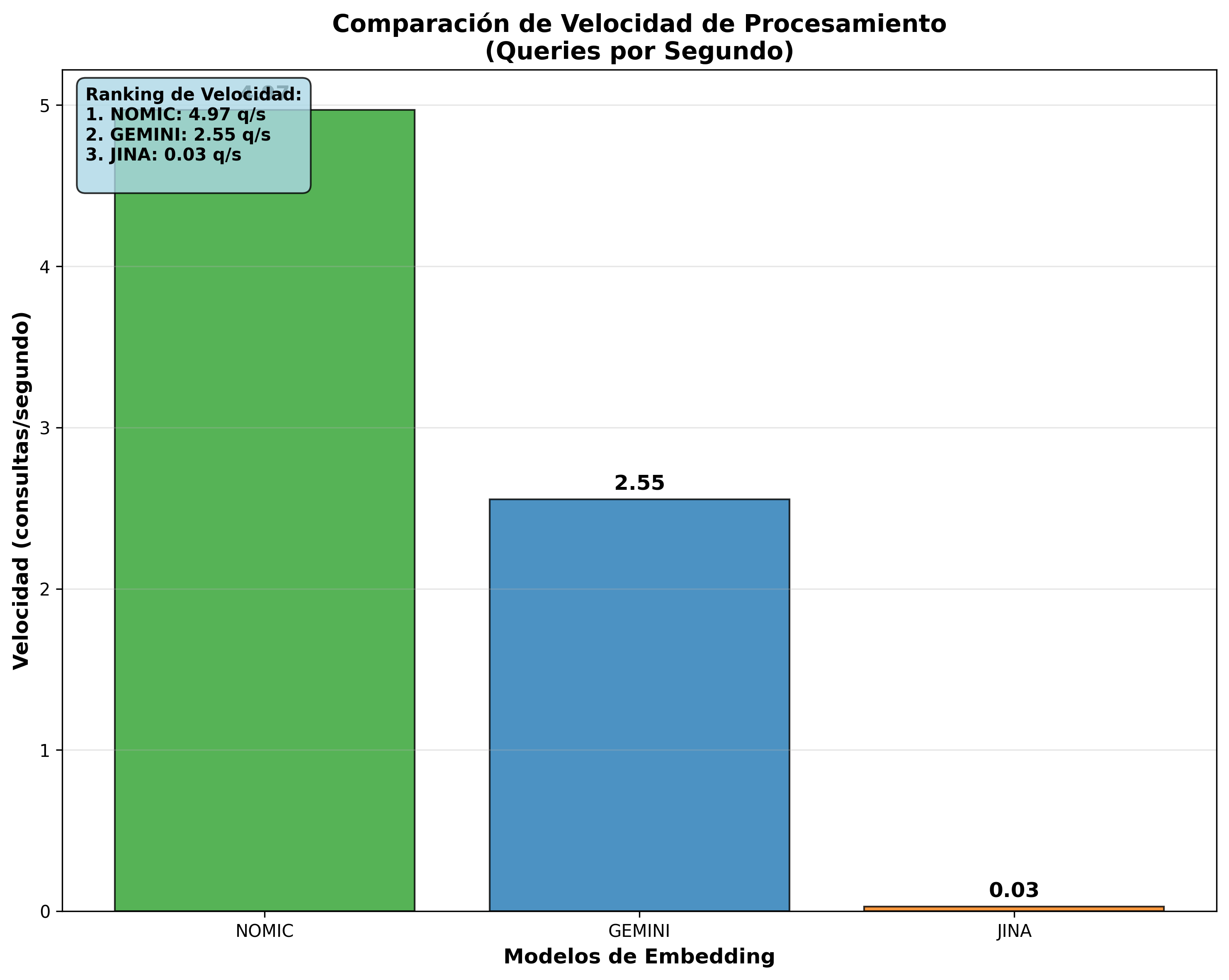
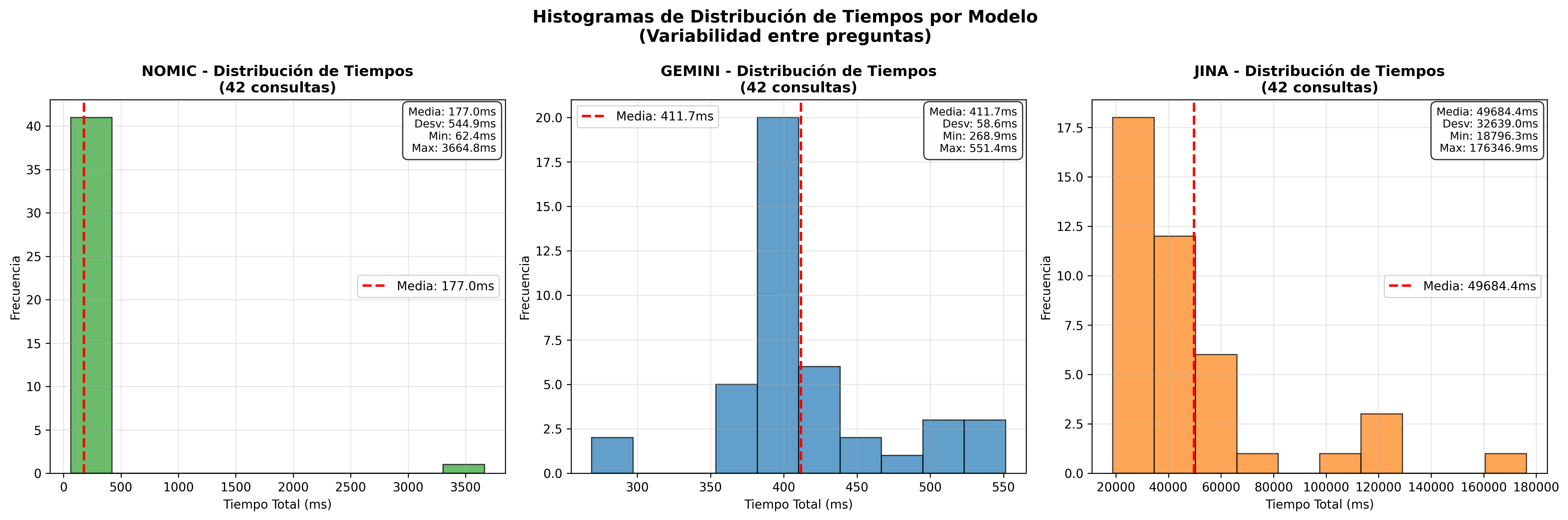
| 1° | Nomic Embed | 201ms | 4.97 | 396.2 |
| 2° | Gemini | 391ms | 2.55 | 354.2 |
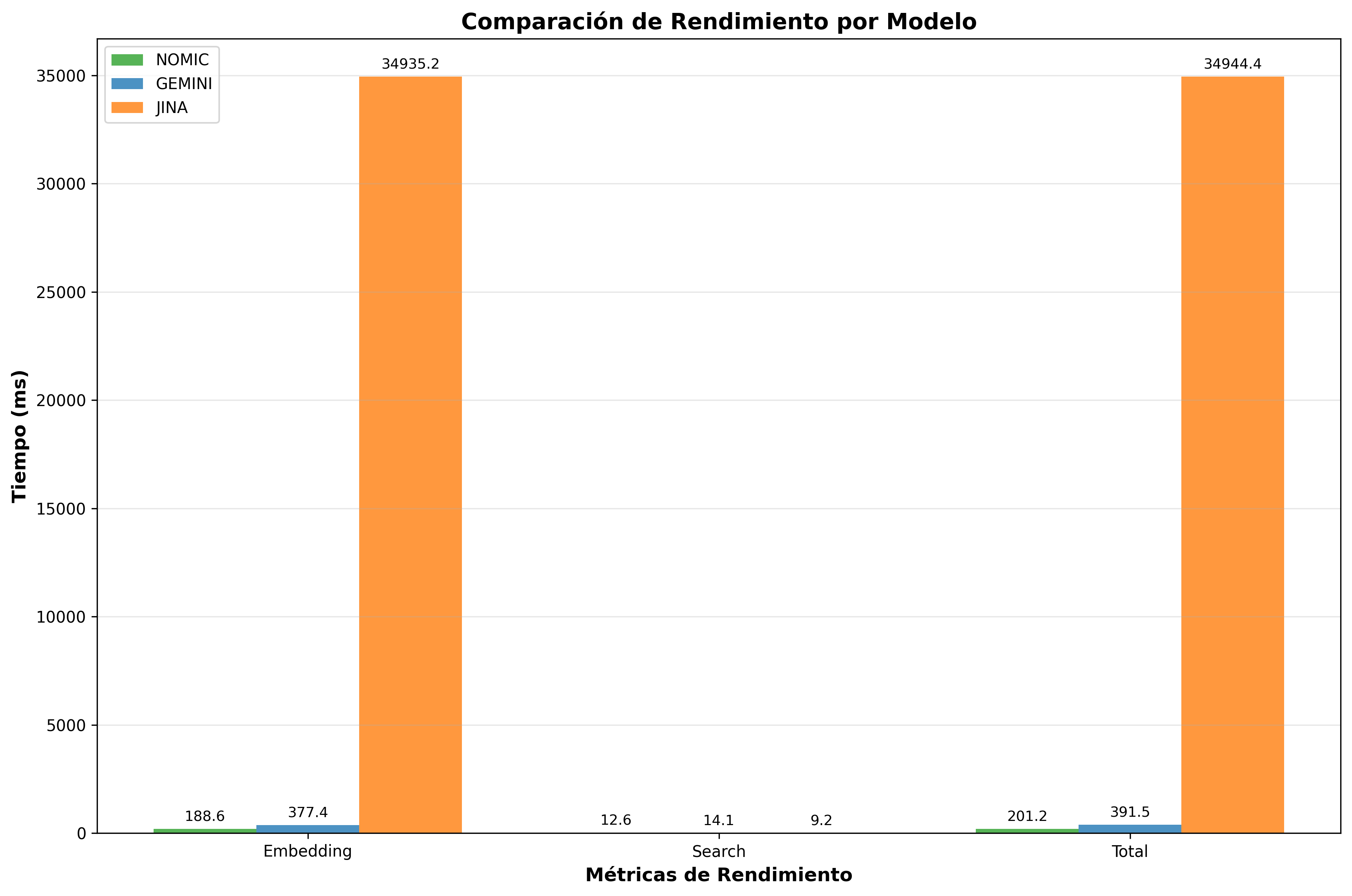
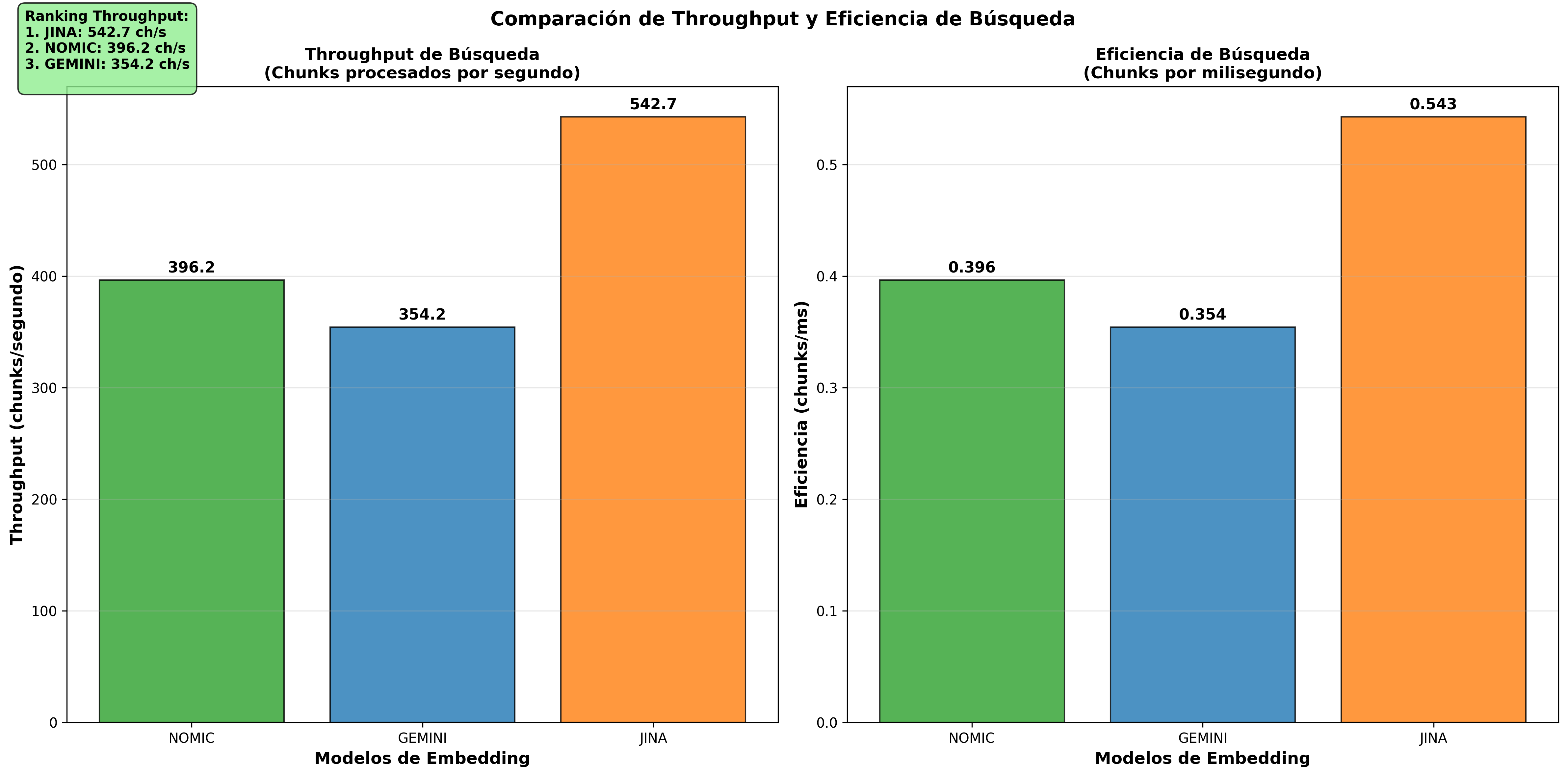
| 3° | Jina | 34,944ms | 0.03 | 542.7 |
Hallazgo importante: Nomic Embed supera significativamente a los modelos basados en API en rendimiento total. Esta ventaja se debe a que mientras Gemini y Jina requieren transmisión de datos a través de internet, Nomic Embed procesa todo localmente. La diferencia es comparable a consultar información almacenada localmente versus realizar una llamada telefónica a larga distancia.
Definición de métricas de rendimiento
Consultas/seg (Queries per Second): Mide la velocidad de procesamiento completo de una consulta, incluyendo tanto la generación del embedding como la búsqueda vectorial. Se calcula como el inverso del tiempo total promedio. Esta métrica representa la capacidad del sistema para atender consultas de usuarios finales.
Chunks/seg (Chunks per Second): Mide la velocidad de procesamiento durante la fase de búsqueda únicamente, calculando cuántos fragmentos de documento pueden ser procesados por segundo durante la comparación vectorial. Esta métrica evalúa la eficiencia del motor de búsqueda independiente de la generación de embeddings.
Análisis 3: Calidad de respuestas
Evaluación basada en la consulta: “¿Cómo pueden las personas ciudadanas afiliarse al IMSS-Bienestar?”
Relevancia con L2
| Modelo | Relevancia Promedio | Categoría | Observación |
|---|---|---|---|
| Gemini | 94.8% | Excelente | Respuestas precisas y contextuales |
| Jina | 92.2% | Excelente | Calidad equiparable, perspectiva diferente |
| Nomic Embed | 92.0% | Muy buena | Funcional y confiable |
Relevancia con Coseno
| Modelo | Relevancia Promedio | Categoría | Observación |
|---|---|---|---|
| Jina | 92.2% | Excelente | Consistente en ambas métricas |
| Gemini | 68.1% | Aceptable | Puntuación más conservadora |
| Nomic Embed | 61.9% | Aceptable | Puntuación más conservadora |
Hallazgo importante: Ambas métricas recuperan exactamente los mismos fragmentos de texto, pero L2 genera puntuaciones 30-35% más optimistas que Coseno. L2 aplica una transformación logarítmica que favorece puntuaciones altas, mientras que Coseno proporciona una evaluación más directa de la similitud angular.
Análisis 4: Estabilidad operacional
La variabilidad en el rendimiento es un factor crítico para sistemas en producción. Un modelo puede ser rápido y preciso, pero la inconsistencia operacional puede generar problemas significativos.
Desviación estándar en L2
| Modelo | Embedding (ms) | Búsqueda (ms) | Evaluación |
|---|---|---|---|
| Gemini | 274.49 | 10.21 | Estable y confiable |
| Nomic Embed | 1958.16 | 9.06 | Muy estable (procesamiento local) |
| Jina | 4607.21 | 4.59 | Variable (servicio gratuito) |
Consideraciones operacionales: Jina, como servicio experimental gratuito, presenta la mayor variabilidad en rendimiento. Gemini mantiene mayor consistencia gracias a su infraestructura empresarial. Nomic Embed demuestra estabilidad predecible debido a su naturaleza local.
Robustez ante calidad de datos
Un hallazgo importante del análisis es que Nomic Embed requiere datos muy limpios para un rendimiento óptimo, mientras que Gemini y Jina demuestran mayor robustez ante datos de calidad variable.
Los datos no limpios afectan a todos los modelos incrementando:
- Consumo de tokens y tiempo de procesamiento
- Agotamiento acelerado de cuotas (relevante para APIs)
- Sobrecarga computacional por contenido mal estructurado
Esta consideración es importante para la selección de modelo según la calidad de los datos de entrada disponibles.
El análisis visual: estructura del espacio vectorial
¿Qué nos dicen las visualizaciones?
Nuestro análisis incluyó extensas visualizaciones que revelan patrones importantes:
Gráficos de rendimiento: Muestran claramente que la búsqueda vectorial es siempre ultrarrápida (menos de 17ms), mientras que la generación de embeddings domina el tiempo total. Es como descubrir que en una carrera de relevos, todos los corredores son igualmente rápidos, pero algunos tardan mucho más en recibir la estafeta.
Métricas de rendimiento
Comparación de velocidad (Performance Comparison)
Las gráficas comparativas revelan que Nomic Embed es consistentemente el más rápido en tiempo total, seguido por Gemini, mientras que Jina presenta alta variabilidad por las limitaciones del servicio gratuito.
- Métrica Coseno:
- Métrica L2:
Análisis de throughput (Velocity & Throughput Comparison)
Estas visualizaciones confirman la superioridad de Nomic Embed en consultas/seg y la eficiencia equivalente en chunks/seg entre todos los modelos.
- Velocity Comparison Coseno:
- Velocity Comparison L2:
- Throughput Comparison Coseno:
- Throughput Comparison L2:
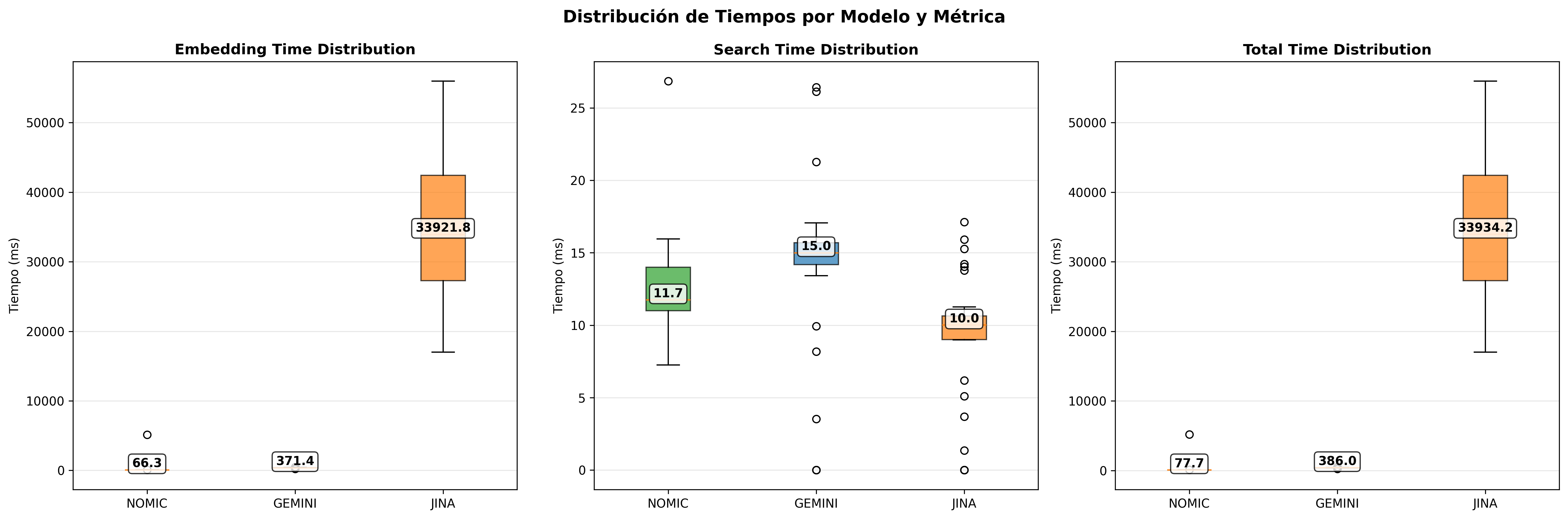
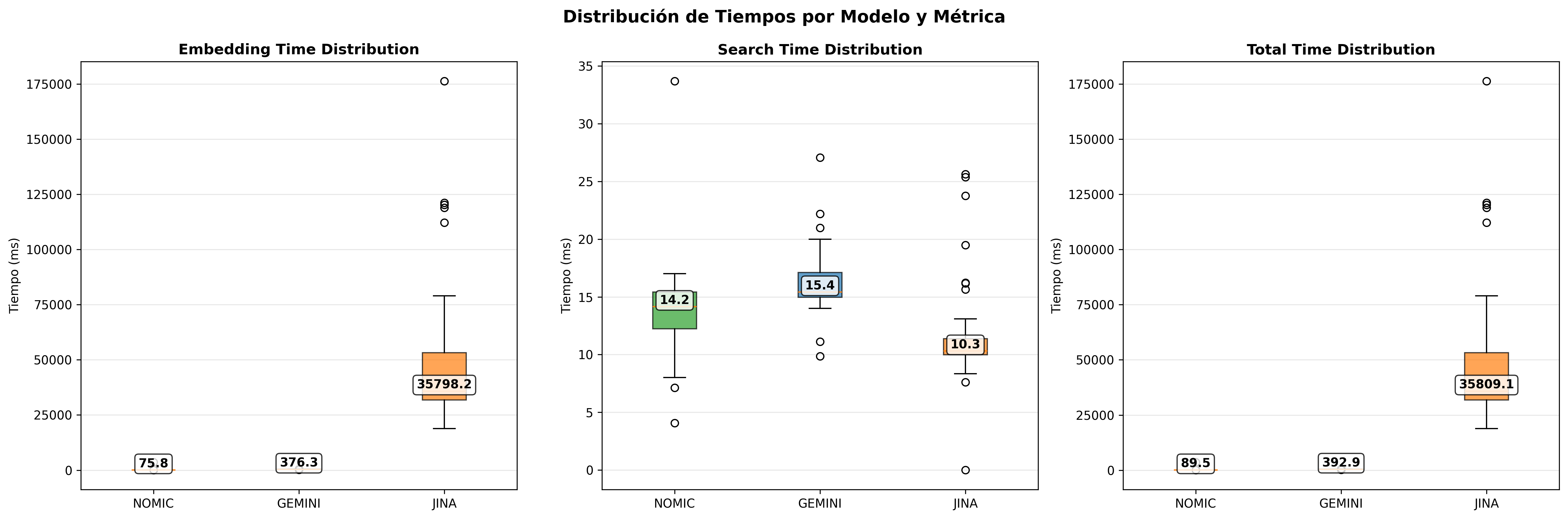
Estabilidad temporal (Boxplots y Histogramas)
Los boxplots revelan que Gemini mantiene estabilidad empresarial, Nomic Embed presenta variaciones predecibles locales, y Jina muestra mayor dispersión por las limitaciones del tier gratuito.
- Performance Boxplots Coseno:
- Performance Boxplots L2:
- Timing Histograms Coseno:
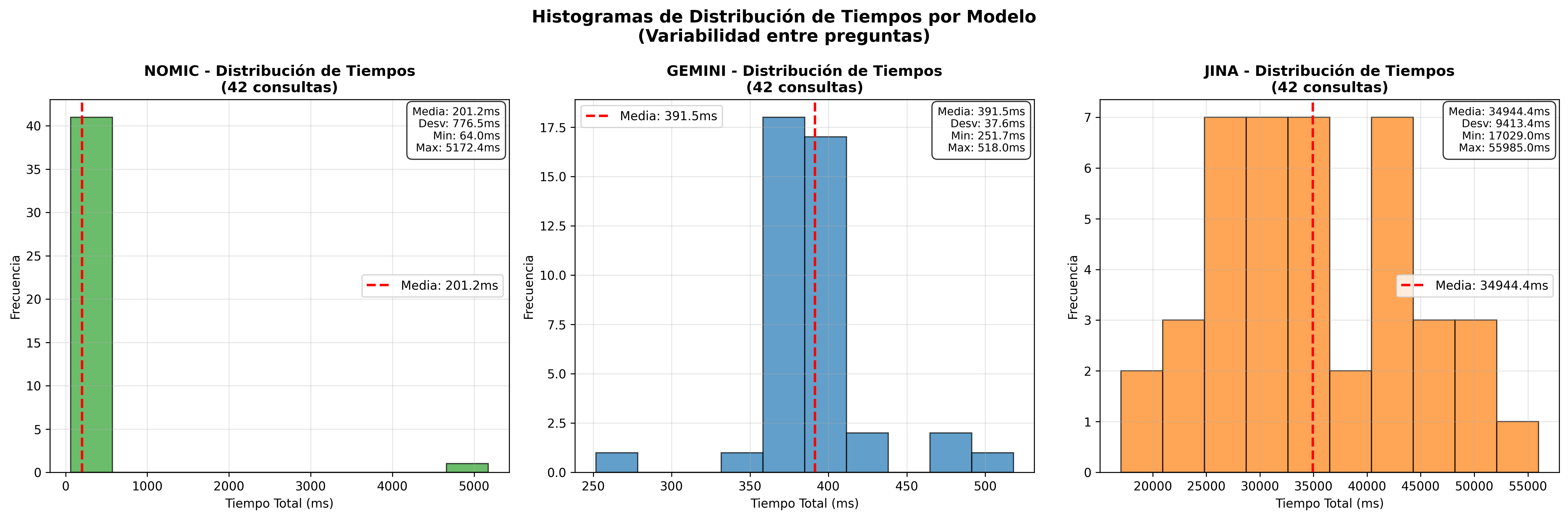
- Timing Histograms L2:
- Timing Scatter Coseno:
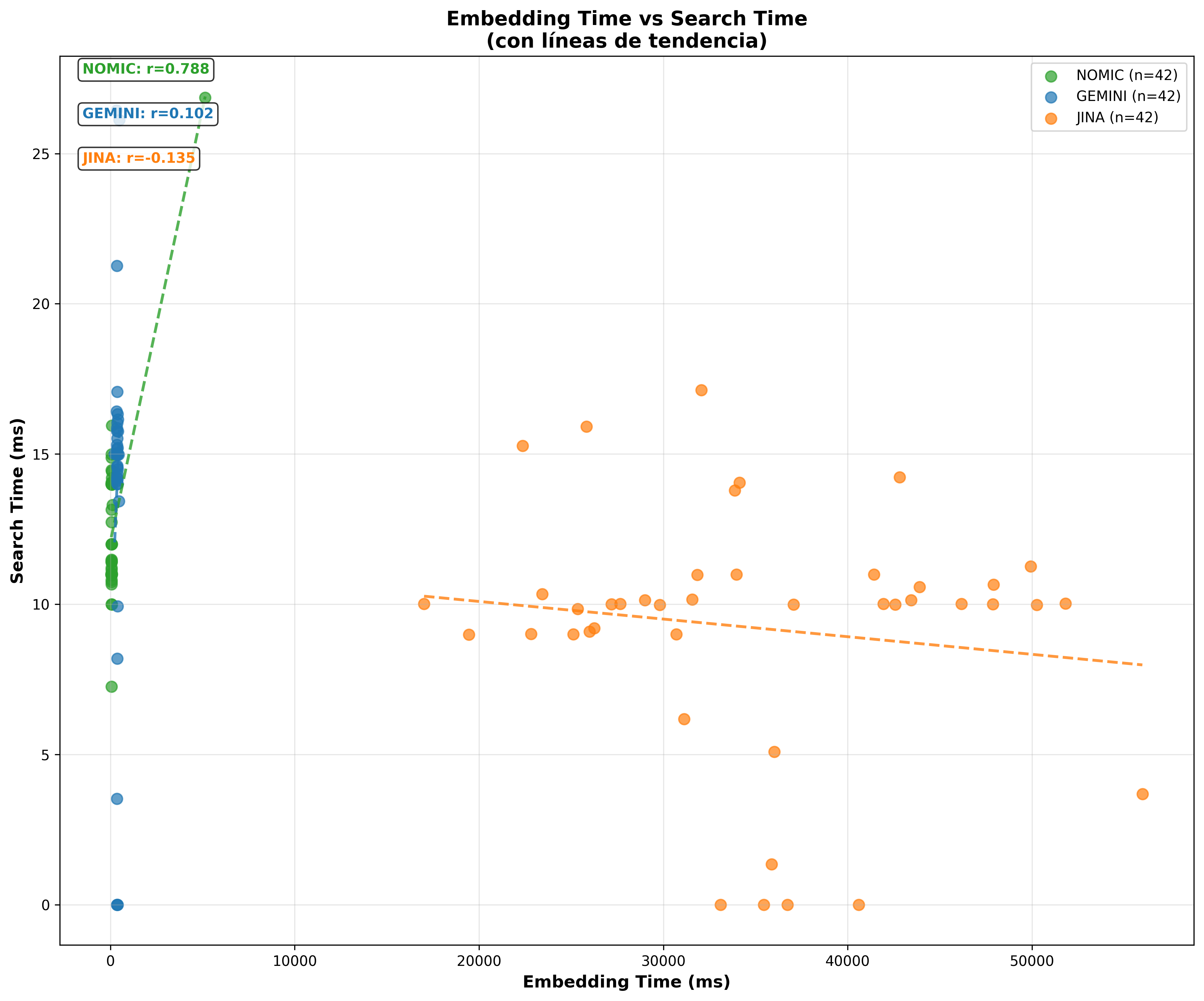 “
“ - Timing Scatter L2:
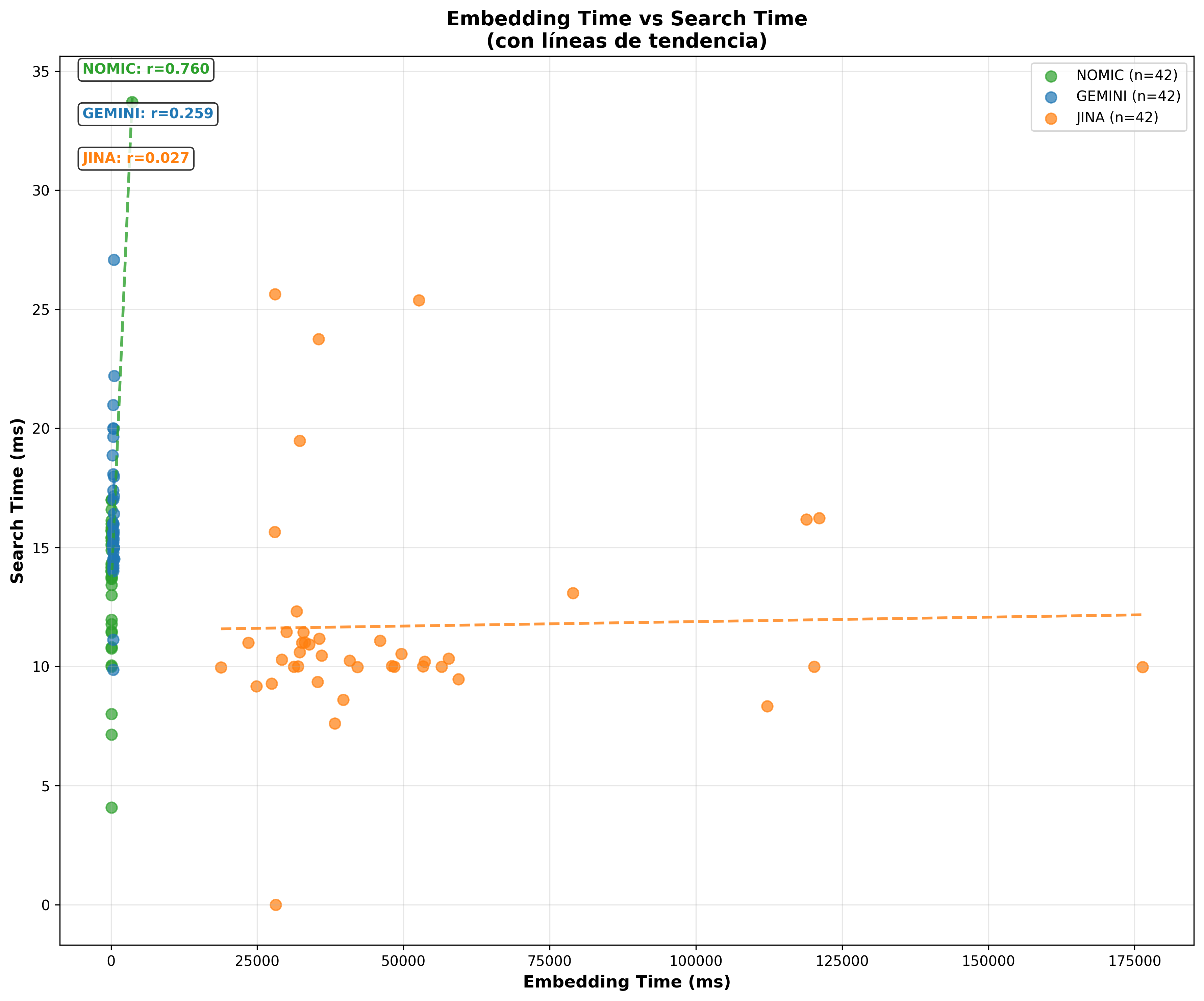 “
“
Visualizaciones del espacio vectorial
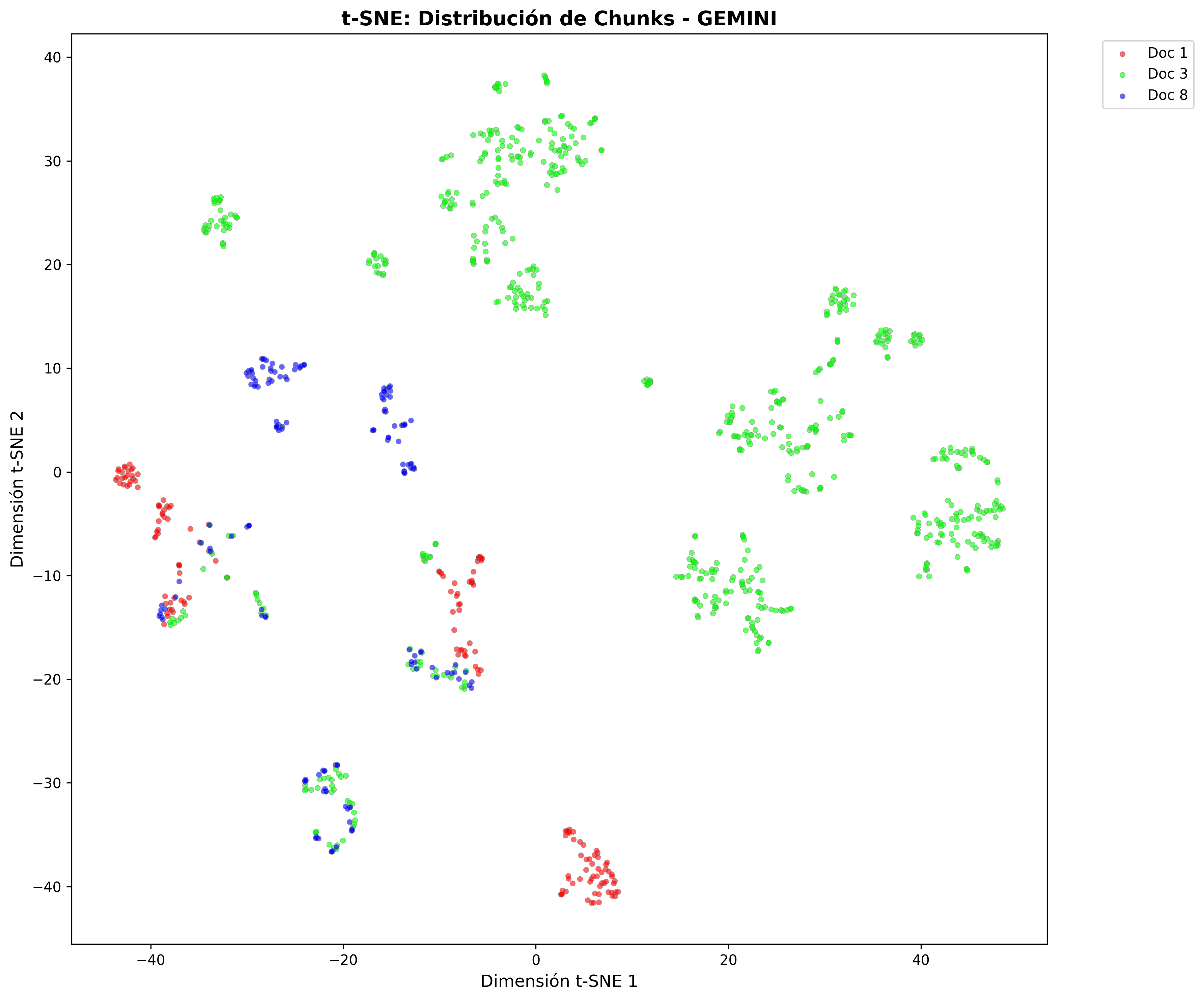
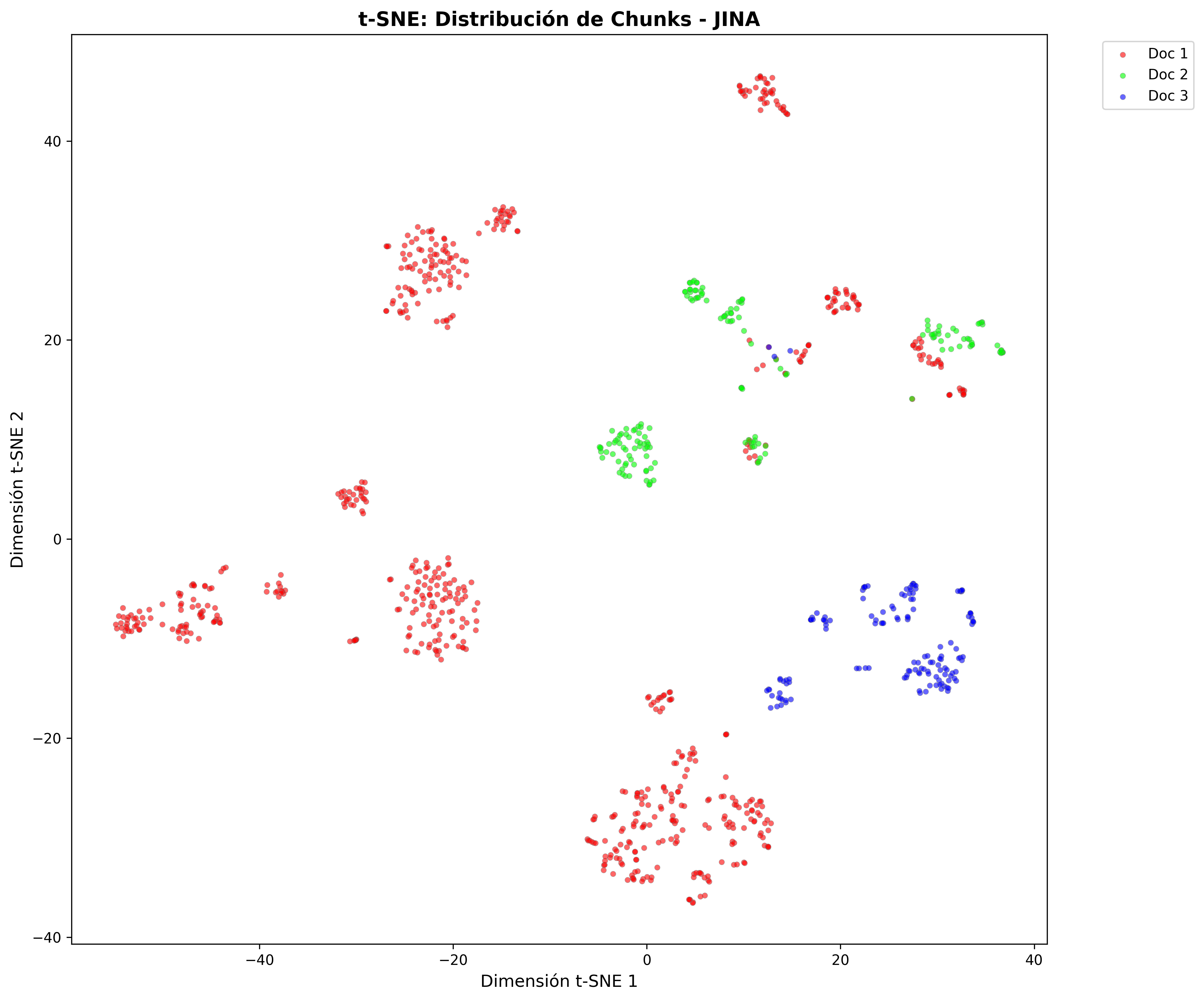
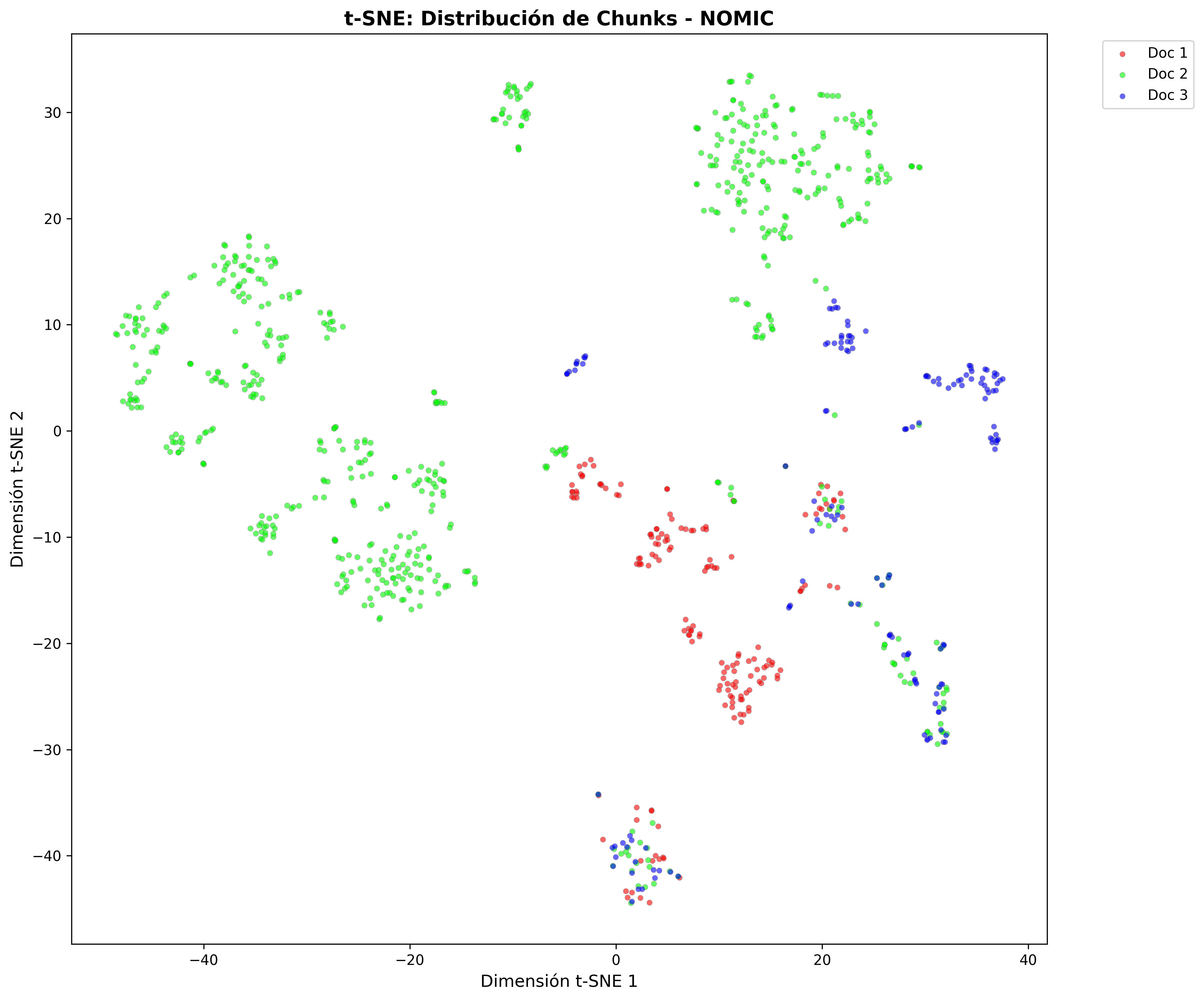
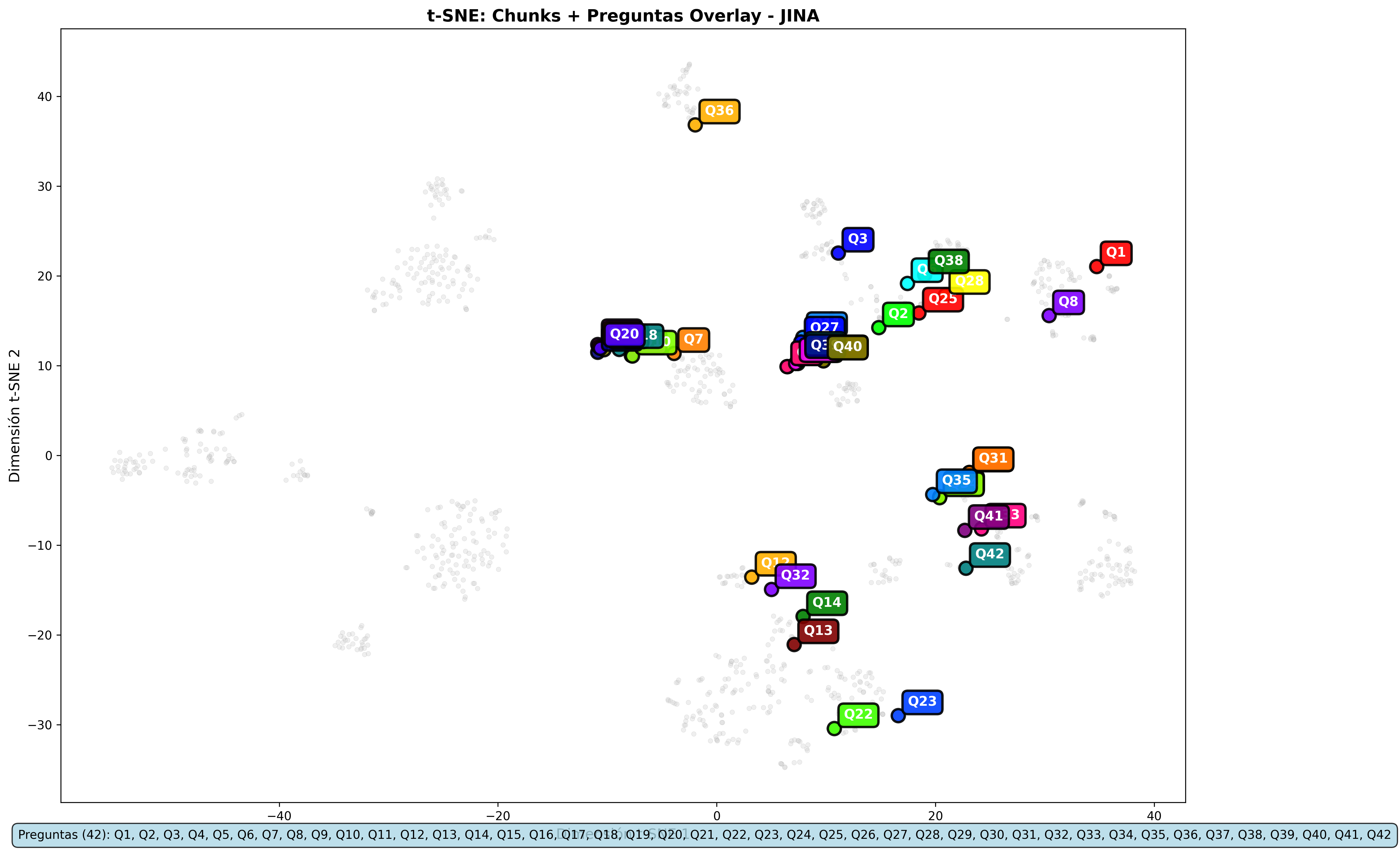
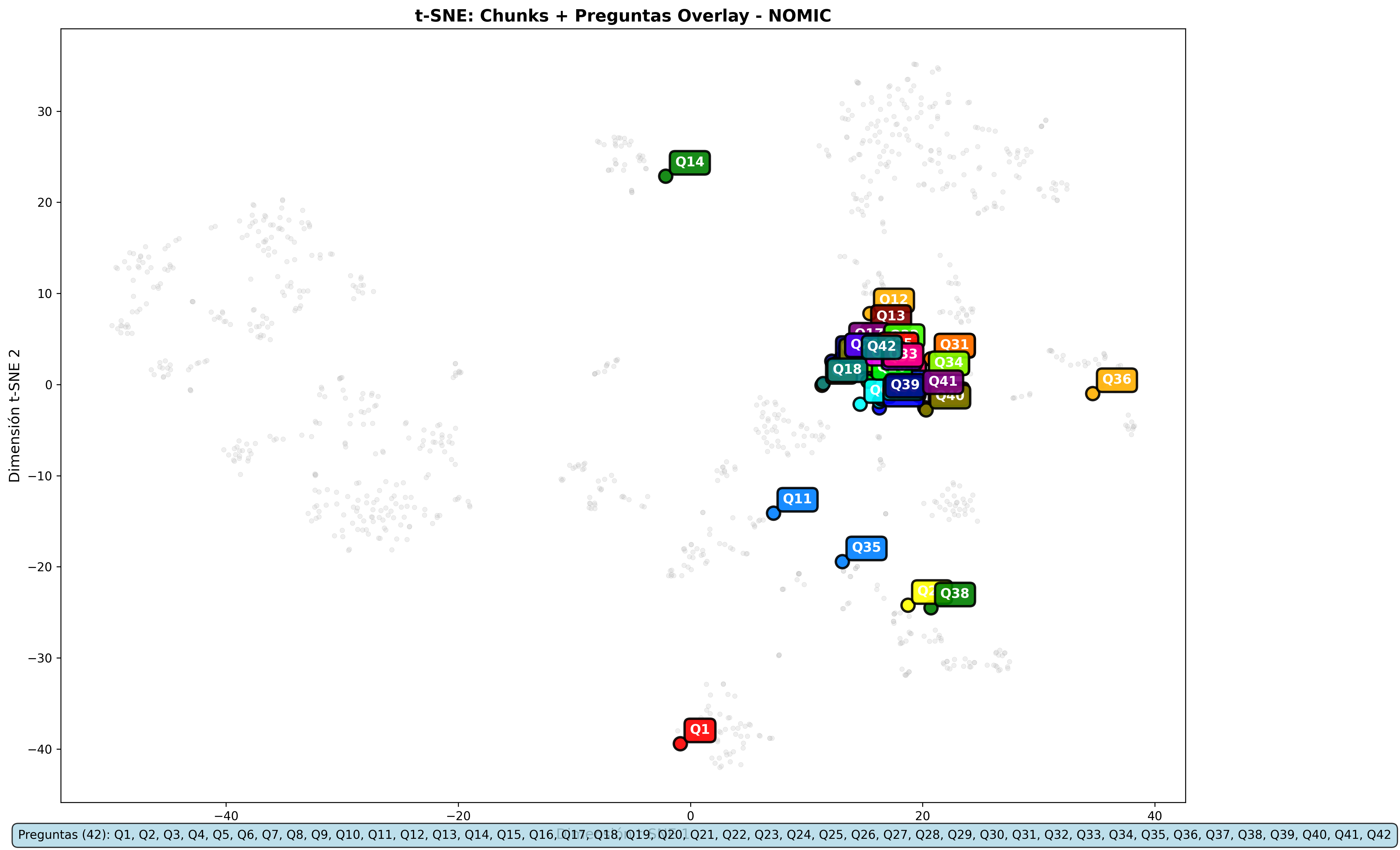
Proyecciones t-SNE: Estas representaciones 2D del espacio vectorial multidimensional revelaron un hallazgo crucial: la estructura espacial de los embeddings es prácticamente idéntica entre L2 y Coseno. Los documentos se agrupan de la misma manera, las consultas caen en los mismos lugares. Solo cambia la forma de medir las distancias.
Estructura de clusters por modelo
Las proyecciones t-SNE muestran cómo cada modelo organiza el contenido en el espacio vectorial:
- Gemini Chunks:
- Jina Chunks:
- Nomic Embed Chunks:
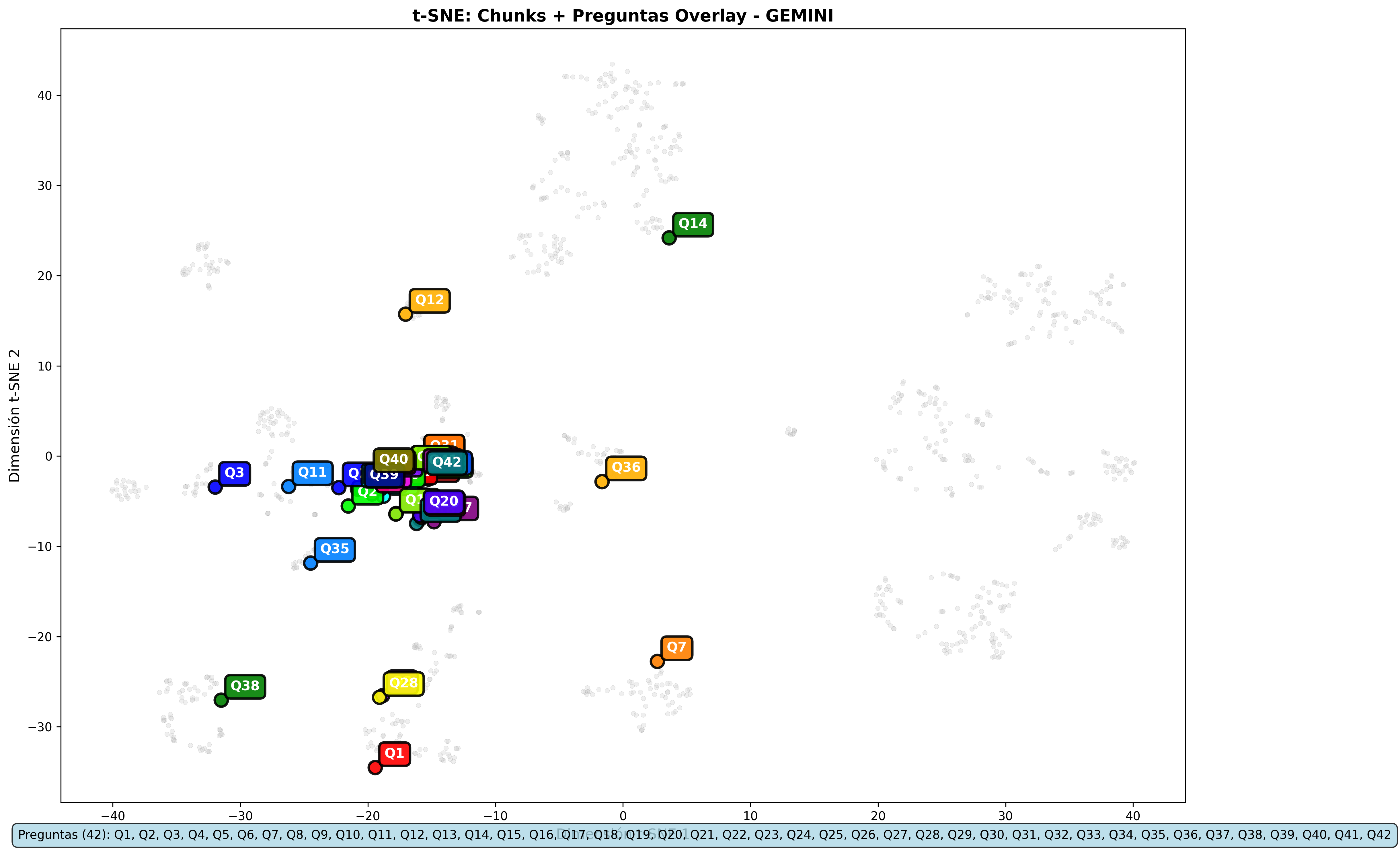
Análisis de overlays por modelo y métrica
Los overlays revelan cómo las consultas se posicionan respecto a los clusters de contenido:
Gemini Overlays:
Jina Overlays:
- Coseno:
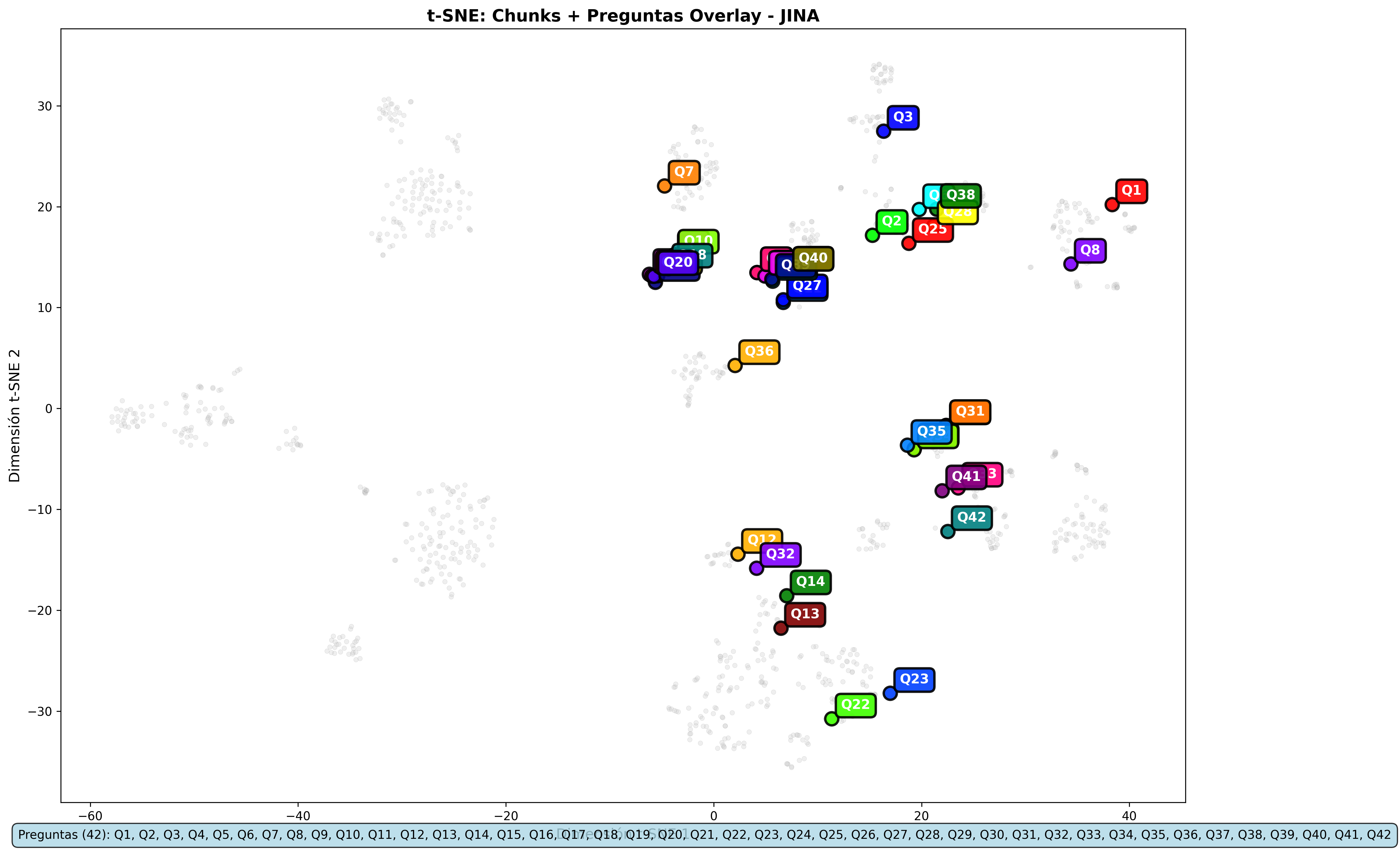
- L2:
Nomic Embed Overlays:
Visualizaciones por modelo:
- Gemini y Nomic Embed: Los overlays son prácticamente idénticos entre métricas
- Jina: Es el único modelo que presenta ligeras variaciones en los overlays entre métricas
Las visualizaciones apoyan las conclusiones numéricas: misma recuperación de contenido, diferencias solo en la escala de relevancia.
La dimensionalidad importa (pero no como esperarías)
Un hallazgo contraintuitivo: Jina (1024D) es el más rápido en búsquedas, seguido por Nomic Embed (768D) y finalmente Gemini (1536D). Esto desafía la intuición de que más dimensiones = más lentitud. La realidad es que la optimización del algoritmo y la implementación importan más que el número bruto de dimensiones.
Aspectos técnicos: bajo el capó
Cómo convertimos distancias en porcentajes
Para L2 (Distancia Euclidiana):
relevancia = 100.0 / (1.0 + distancia / 10.0)Esta fórmula logarítmica comprime las diferencias, haciendo que distancias pequeñas se traduzcan en relevencias muy altas.
Para Coseno (Similitud Angular):
relevancia = similitud x 100.0Una conversión directa y lineal que refleja exactamente la similitud angular.
Los límites operacionales
Los servicios de API presentan limitaciones que influyen en el rendimiento:
Gemini: 15 peticiones por minuto, 1000 peticiones por día Jina: 10 millones de tokens, procesamiento con baja prioridad
Estas limitaciones explican parcialmente la variabilidad observada en los tiempos de respuesta y hacen que soluciones locales como Nomic Embed ofrezcan ventajas de predictibilidad.
Conclusiones: cuando la teoría se encuentra con la realidad
Evaluación comparativa final
Para velocidad y autonomía operacional: Nomic Embed demuestra superioridad clara. Sin dependencias externas, sin límites de API, con rendimiento predecible. Representa una solución robusta y autónoma para entornos con requisitos de disponibilidad constante.
Para calidad semántica superior: Gemini ofrece la mejor experiencia cuando la precisión es prioritaria. Proporciona embeddings de alta calidad con infraestructura empresarial confiable, aunque con limitaciones de uso que requieren planificación.
Para balance calidad-disponibilidad: Jina ofrece buen rendimiento cuando el servicio opera óptimamente. Útil como alternativa especializada, aunque con variabilidad inherente a servicios gratuitos.
L2 vs Coseno: análisis comparativo
Después de 42 consultas y análisis exhaustivos, los datos muestran que ambas métricas son funcionalmente equivalentes. Las diferencias principales:
- Recuperan exactamente el mismo contenido
- Diferencias de velocidad mínimas (~2ms)
- Mantienen estructura espacial idéntica
- Solo difieren en escalas de puntuación
La selección entre ambas puede basarse en preferencias de interpretación: Coseno ofrece puntuaciones más conservadoras y directamente interpretables, mientras que L2 proporciona puntuaciones más optimistas debido a su transformación logarítmica.
La estrategia híbrida: lo mejor de ambos mundos
Para proyectos grandes como DOF-RAG, la solución óptima es una estrategia híbrida:
- Gemini para documentos críticos donde la precisión es fundamental
- Nomic Embed para procesamiento masivo donde podemos aceptar un margen de error mayor
- Jina como respaldo para casos especiales que requieren una perspectiva diferente
Recomendaciones prácticas
Para autonomía operacional completa: Nomic Embed es la elección óptima. El sistema nunca dependerá de APIs externas y mantendrá rendimiento predecible.
Para máxima calidad semántica: Gemini ofrece la mejor experiencia cuando la precisión es prioritaria, aunque requiere gestión de límites de API.
Para experimentación con presupuesto limitado: Jina proporciona una opción viable para prototipos, aunque con variabilidad en tiempos de respuesta.
Sobre selección de métrica: Coseno para puntuaciones conservadoras e interpretables; L2 para puntuaciones optimistas. Ambas ofrecen rendimiento equivalente en recuperación de contenido.
Reflexiones finales: el futuro de la búsqueda semántica
Este análisis nos ha enseñado que en el mundo de los embeddings, como en muchos aspectos de la tecnología, no existe una solución única que sea perfecta para todos los casos. La elección del modelo correcto depende de tus prioridades específicas: ¿autonomía o calidad? ¿velocidad o precisión? ¿costo o rendimiento?
Lo que sí queda claro es que los embeddings vectoriales han democratizado la búsqueda semántica sofisticada. Modelos que hace unos años requerían infraestructuras millonarias ahora pueden ejecutarse en una laptop modesta. El futuro de la búsqueda inteligente no está en manos de unos pocos gigantes tecnológicos, sino al alcance de cualquiera con curiosidad suficiente para experimentar.
Y quizás esa sea la lección más importante: en la era de la IA, el conocimiento técnico sigue siendo poder, pero el poder real está en saber cómo aplicar esas herramientas para resolver problemas reales de personas reales.
Este análisis forma parte de nuestro proyecto DOF-RAG para hacer más accesible la información gubernamental mexicana. Para más detalles técnicos, metodología completa y acceso al código fuente, consulta nuestro repositorio.
Datos del análisis:
- Período de evaluación: Agosto 2025
- Consultas analizadas: 42 preguntas representativas
- Fragmentos procesados: Más de 1000 chunks de documentos DOF
- Herramientas utilizadas: DuckDB, Python, métodos nativos de similitud vectorial
Comentarios