The Battle of Embeddings: When Three AI Models Compete to Understand Governmental Spanish
A comparative analysis of three embedding models (Nomic Embed, Gemini, Jina) evaluating speed, quality, and stability in vector search for Mexican official documents.

When Algorithms Face Mexican Bureaucratic Language
In the world of artificial intelligence, one of the most important analyses in natural language processing is evaluating how different embedding models understand and represent the complex universe of Mexican governmental language. In this study we analyze three embedding models: Nomic Embed (local model), Gemini (Google API), and Jina (specialized in vector search). Their goal: to decipher, understand, and perform effective searches across thousands of documents from the Official Journal of the Federation (DOF).
The results reveal significant differences in speed, precision, and the operational advantages of local solutions versus cloud APIs.
Key Findings
Main conclusions from the study:
- Gemini offers superior response quality, followed by Jina with equivalent quality but a different perspective, and Nomic Embed with functional quality
- Similarity metrics show negligible performance differences (~2ms)
- Nomic Embed leads in operational performance and stability, but requires very clean data, while Gemini and Jina are robust with variable-quality data
- Both metrics retrieve identical content, differing only in the relevance scoring scale
- The model decision should prioritize response quality vs. operational autonomy based on specific business needs
The Challenge: Vector Search Analysis in Government Documents
When building Retrieval-Augmented Generation (RAG) systems like DOF-RAG, we face a problem that goes far beyond traditional keyword search. Citizens don’t search using the exact same words that appear in official documents. Someone might ask “How do I enroll in IMSS-Bienestar?” while the official document refers to “procedures for incorporation into the social security regime.”
This is where vector embeddings come in: mathematical representations that capture the semantic meaning of text, allowing the system to understand that both phrases refer to the same concept, even though they use completely different words.
This analysis is based on 42 representative queries processed against more than 5,000 document chunks from the DOF, evaluating both search speed and response quality using native DuckDB methods.
But the key question arises: which embedding model works best for Mexican government documents? And more importantly: does it really matter whether we use Euclidean distance (L2) or cosine similarity?
The Evaluated Models: Features and Technical Specifications
🏠 Nomic Embed: Local Model
Technical Characteristics: A completely local model (modernbert-embed-base) that operates without internet dependencies.
Specifications:
- Dimensions: 768 (compact and efficient architecture)
- Size: ~596 MB (feasible for standard hardware)
- Main advantage: Zero network latency
- Operational profile: Reliable model for environments requiring constant availability
Selection Justification: Represents total operational independence. In scenarios where connectivity is limited, APIs are unavailable, or there are budget constraints, Nomic Embed maintains full functionality.
🌟 Gemini: Google Commercial API
Technical Characteristics: Google’s embedding model with enterprise cloud infrastructure.
Specifications:
- Dimensions: 1536 (high dimensionality for complex semantic representation)
- Speed: 3-5 seconds per query
- Quality: Advanced contextual understanding
- Limitations: 15 requests per minute, 1000 requests per day (free plan)
Selection Justification: Gemini represents the current state of commercial embeddings, combining superior semantic quality with the stability and reliability of Google’s infrastructure.
Free Plan Considerations: When using Gemini’s free tier, we are subject to limitations of 15 requests per minute and 1000 daily requests.
🎯 Jina: Specialized Embedding API
Technical Characteristics: A company specialized exclusively in embeddings and vector search.
Specifications:
- Dimensions: 1024 (intermediate dimensionality)
- Specialization: Specific optimization for vector search
- Plan: Free with 10 million tokens available
- Operational profile: Specialized model with variable performance depending on service availability
Selection Justification: Jina offers a specialized perspective in the embedding ecosystem, providing a valuable comparison point between local solutions and general-purpose commercial APIs.
Free Plan Limitations: Jina offers 10 million tokens to process, but since it’s an experimental plan, requests are processed with low priority, resulting in variable response times.
Cloud Service Considerations
Both Gemini and Jina operate under free plans, which introduces important operational limitations that explain some of the variability observed in the results, especially for Jina which showed average response times of 30-50 seconds.
This reality means that Nomic Embed, despite its lower semantic quality, offers significant advantages in autonomy and operational predictability.
Evaluation Methodology: Native DuckDB Methods
To ensure a fair comparison between models, we used native DuckDB methods — optimized functions (array_cosine_similarity() and array_distance()) that are 35-50 times faster than manual Python implementations.
Performance Impact: The practical difference is substantial: going from searches that required 500-800ms to optimized searches of 9-16ms. This improvement is comparable to the difference between processing data manually versus using highly optimized algorithms.
L2 vs Cosine: The Eternal Question
L2 (Euclidean) Distance: Measures how “far” two vectors are in mathematical space. Like measuring the distance between two points on a map.
Cosine Similarity: Measures how “aligned” two vectors are, ignoring their magnitude. Like checking whether two arrows point in the same direction, regardless of their size.
The question everyone asks: does it matter which one you use? Spoiler: less than you’d think.
The Results: When Numbers Speak for Themselves
Analysis 1: Vector Search Speed
| Model | L2 (ms) | Cosine (ms) | Difference | Observation |
|---|---|---|---|---|
| Nomic Embed | 14.03 | 12.62 | +1.41ms | Cosine slightly faster |
| Gemini | 16.20 | 14.12 | +2.08ms | Cosine slightly faster |
| Jina | 11.69 | 9.21 | +2.48ms | Cosine slightly faster |
Key Finding: The average difference of ~2ms between L2 and Cosine is practically negligible for production applications. This difference is comparable to debating whether a task completes in 4.012 seconds versus 4.014 seconds: technically measurable, practically irrelevant.
Analysis 2: Total Performance (Embedding + Search)
This analysis examines not only search speed but also the processing speed for generating embeddings of new queries.
L2 Metric
| Position | Model | Total Time | Queries/sec | Chunks/sec |
|---|---|---|---|---|
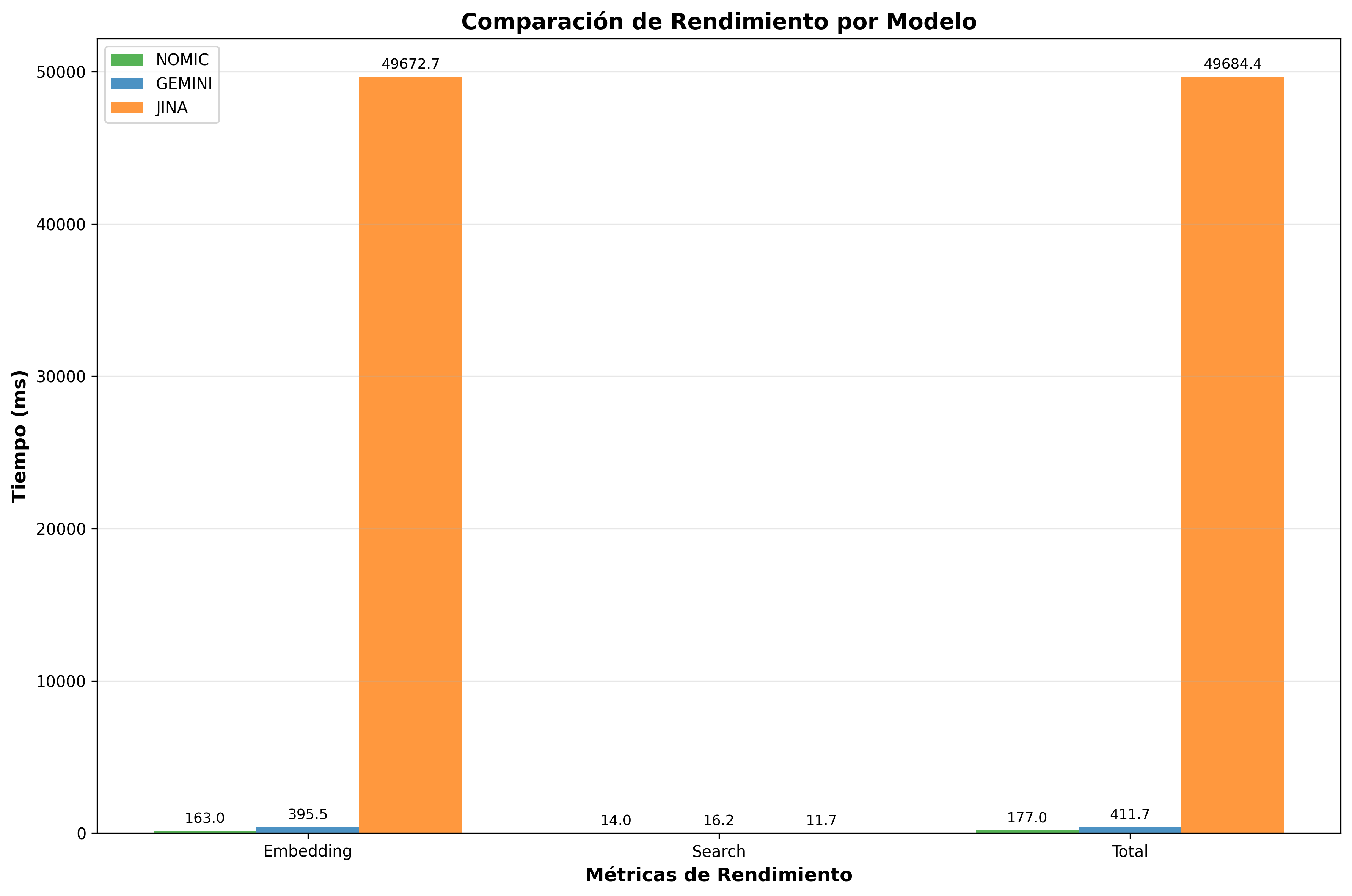
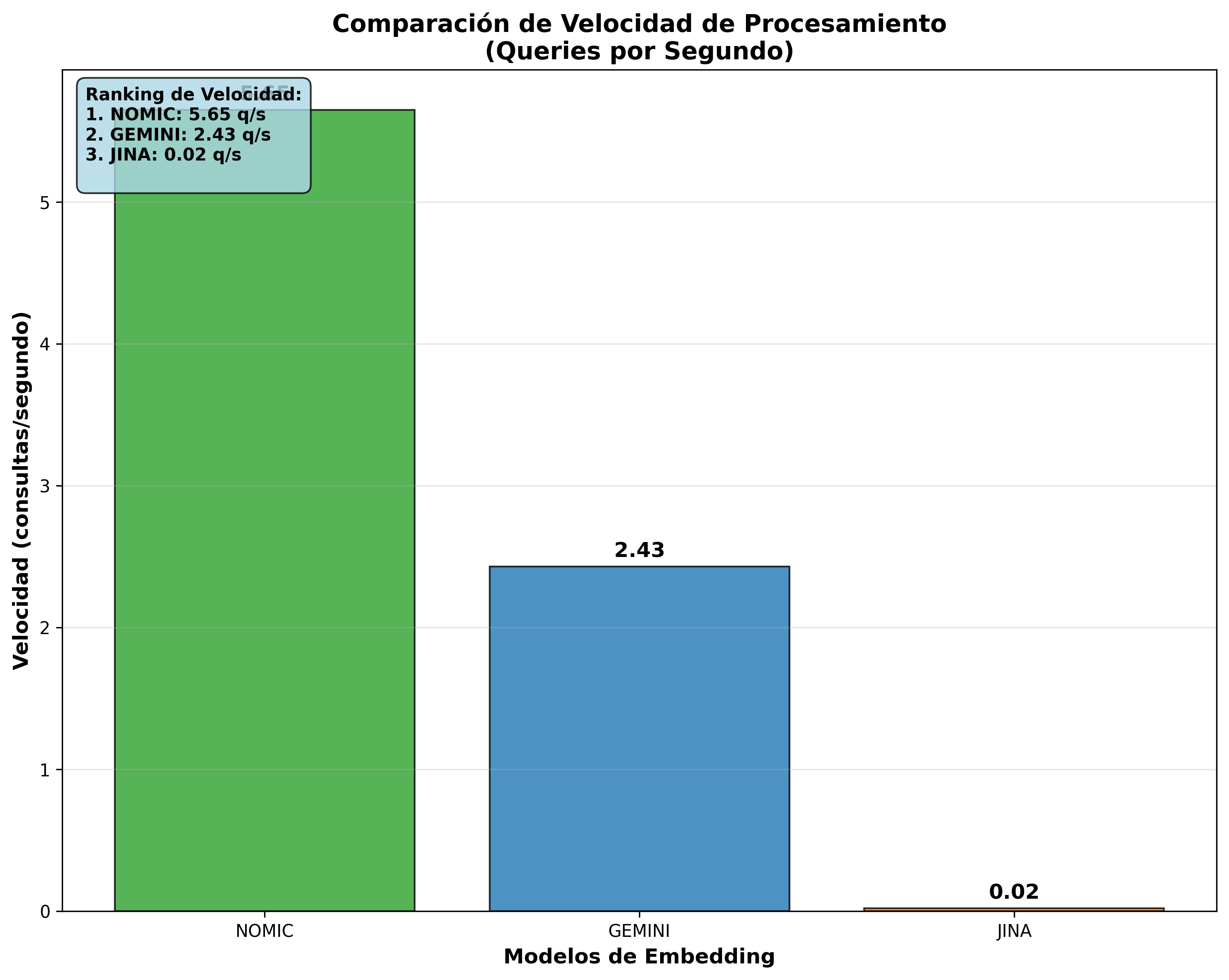
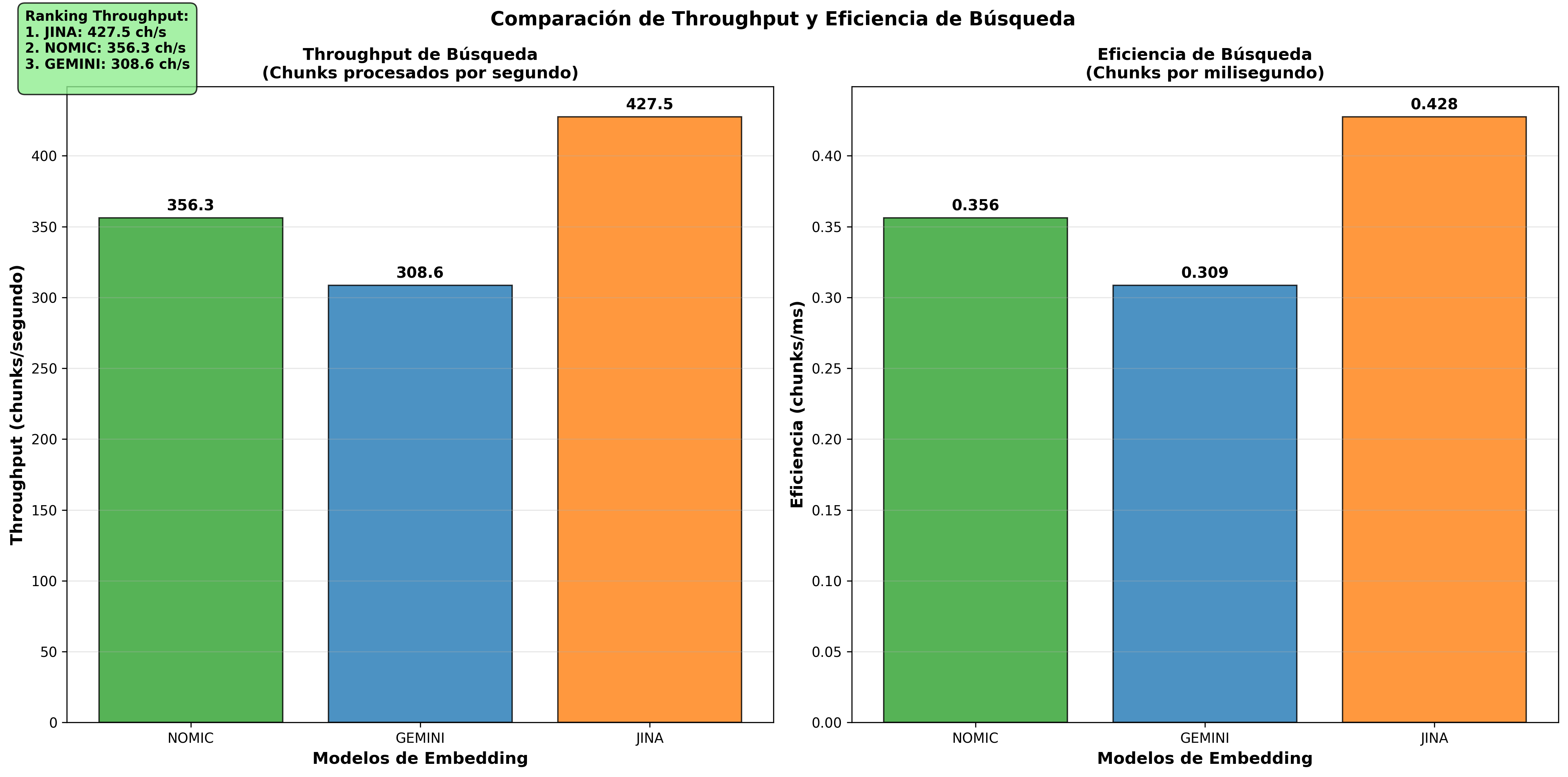
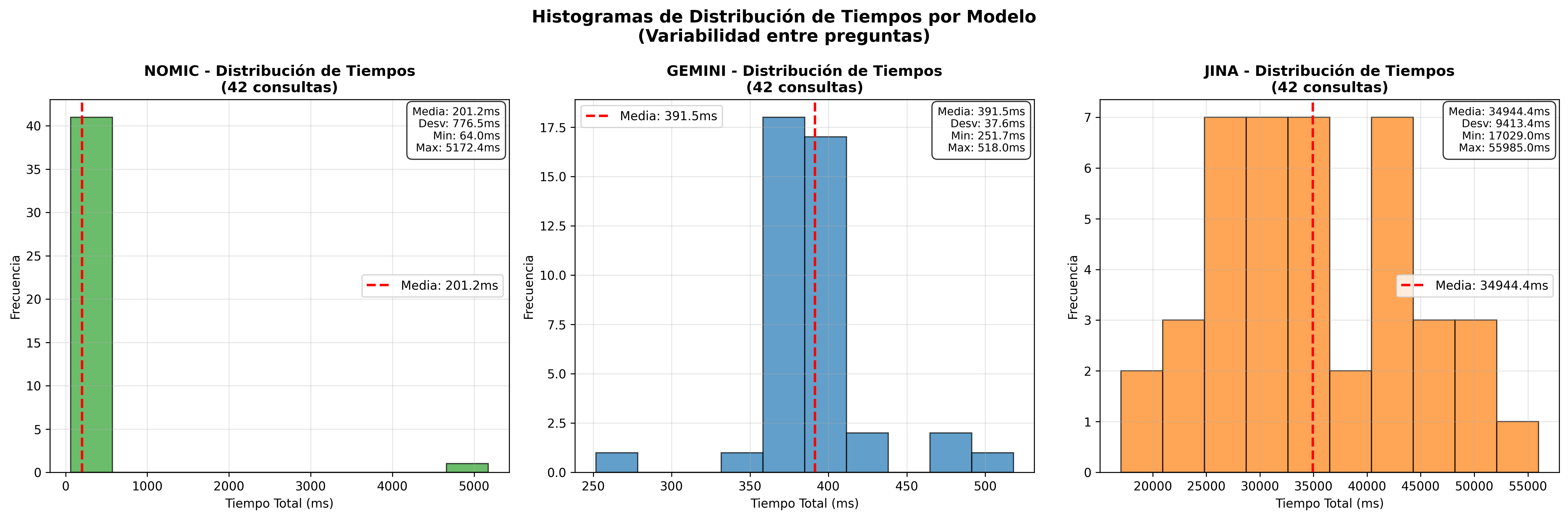
| 1st | Nomic Embed | 177ms | 5.65 | 356.3 |
| 2nd | Gemini | 412ms | 2.43 | 308.6 |
| 3rd | Jina | 49,684ms | 0.02 | 427.5 |
Cosine Metric
| Position | Model | Total Time | Queries/sec | Chunks/sec |
|---|---|---|---|---|
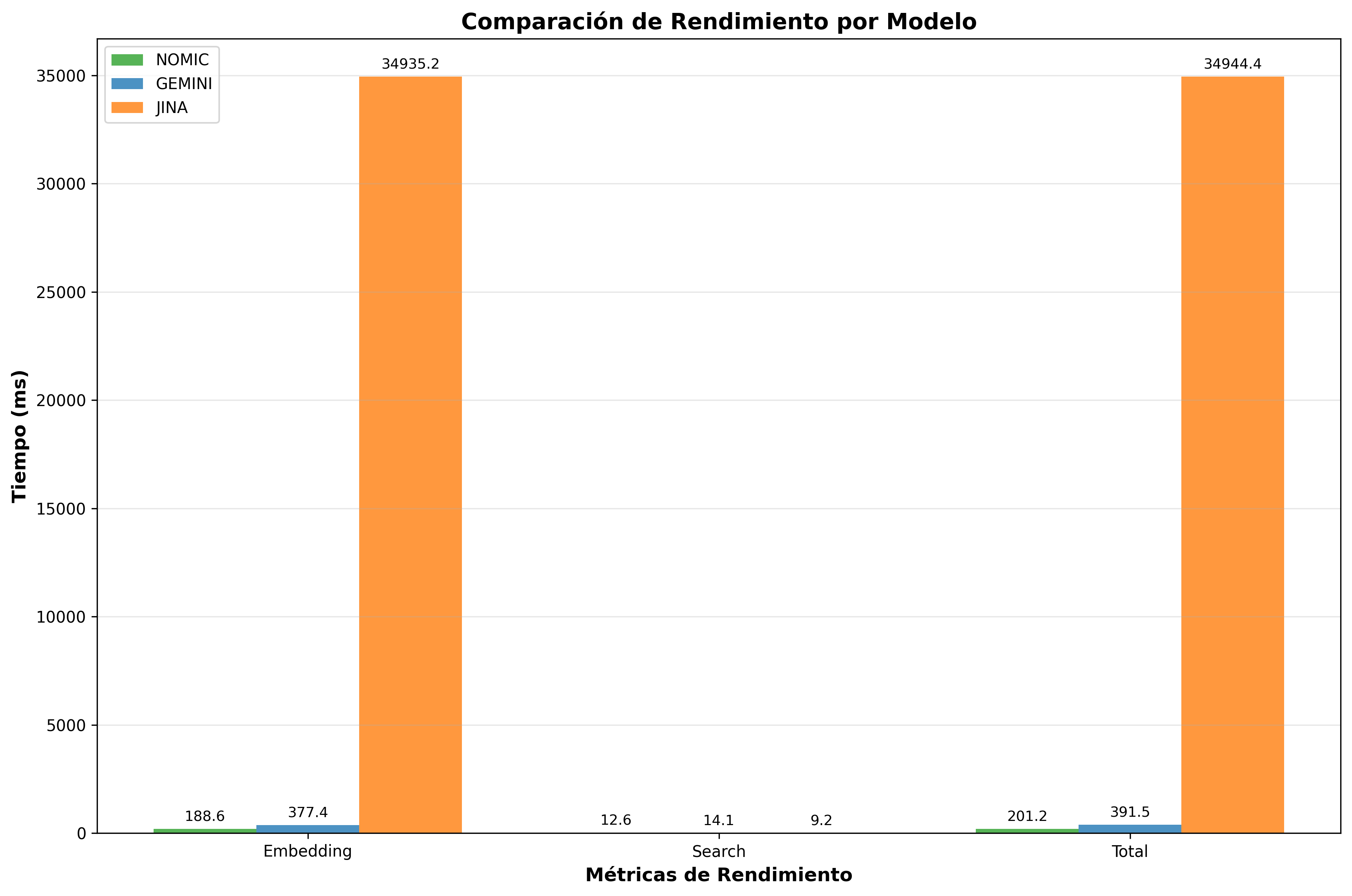
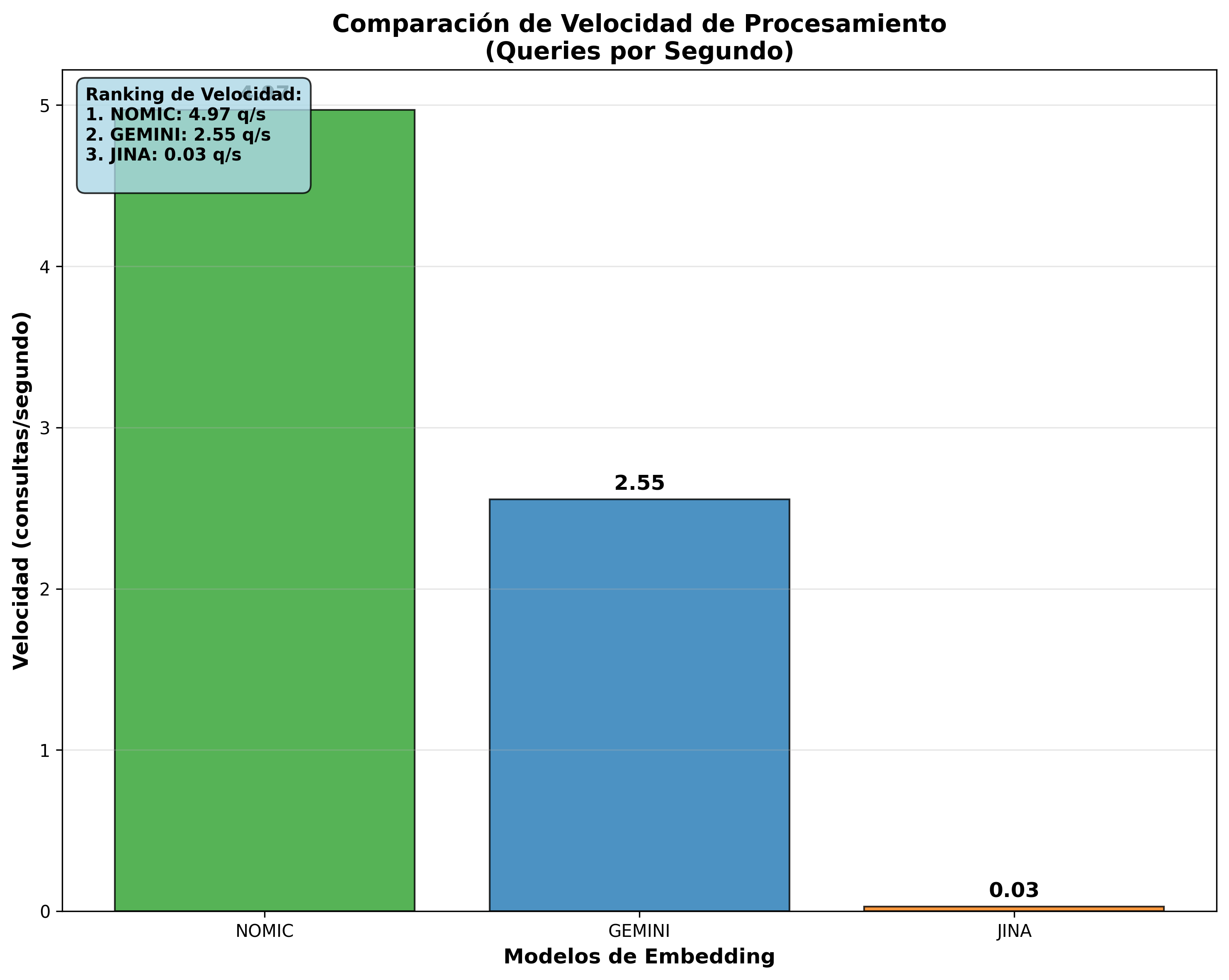
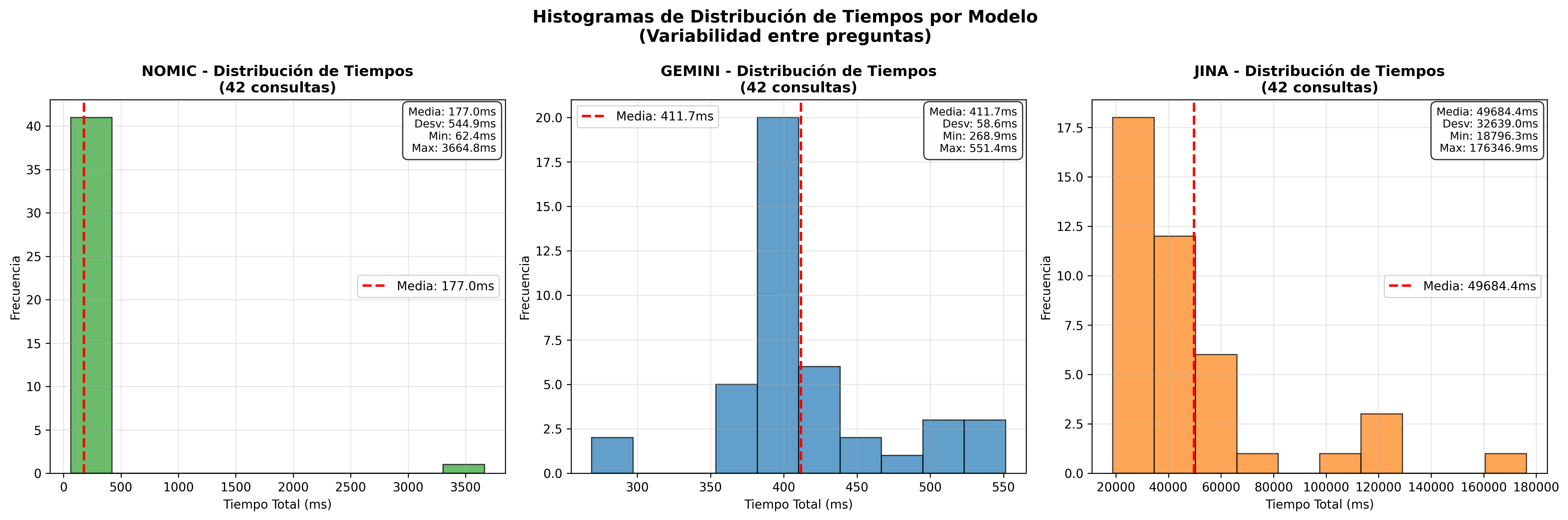
| 1st | Nomic Embed | 201ms | 4.97 | 396.2 |
| 2nd | Gemini | 391ms | 2.55 | 354.2 |
| 3rd | Jina | 34,944ms | 0.03 | 542.7 |
Key Finding: Nomic Embed significantly outperforms API-based models in total performance. This advantage comes from the fact that while Gemini and Jina require data transmission over the internet, Nomic Embed processes everything locally. The difference is comparable to looking up locally stored information versus making a long-distance phone call.
Performance Metrics Definition
Queries/sec (Queries per Second): Measures the complete processing speed of a query, including both embedding generation and vector search. Calculated as the inverse of the average total time. This metric represents the system’s capacity to serve end-user queries.
Chunks/sec (Chunks per Second): Measures the processing speed during the search phase only, calculating how many document chunks can be processed per second during vector comparison. This metric evaluates search engine efficiency independent of embedding generation.
Analysis 3: Response Quality
Evaluation based on the query: “How can citizens enroll in IMSS-Bienestar?”
Relevance with L2
| Model | Average Relevance | Category | Observation |
|---|---|---|---|
| Gemini | 94.8% | Excellent | Precise and contextual responses |
| Jina | 92.2% | Excellent | Comparable quality, different perspective |
| Nomic Embed | 92.0% | Very Good | Functional and reliable |
Relevance with Cosine
| Model | Average Relevance | Category | Observation |
|---|---|---|---|
| Jina | 92.2% | Excellent | Consistent across both metrics |
| Gemini | 68.1% | Acceptable | More conservative scoring |
| Nomic Embed | 61.9% | Acceptable | More conservative scoring |
Key Finding: Both metrics retrieve exactly the same text chunks, but L2 generates 30-35% more optimistic scores than Cosine. L2 applies a logarithmic transformation that favors high scores, while Cosine provides a more direct evaluation of angular similarity.
Analysis 4: Operational Stability
Performance variability is a critical factor for production systems. A model can be fast and accurate, but operational inconsistency can cause significant problems.
Standard Deviation in L2
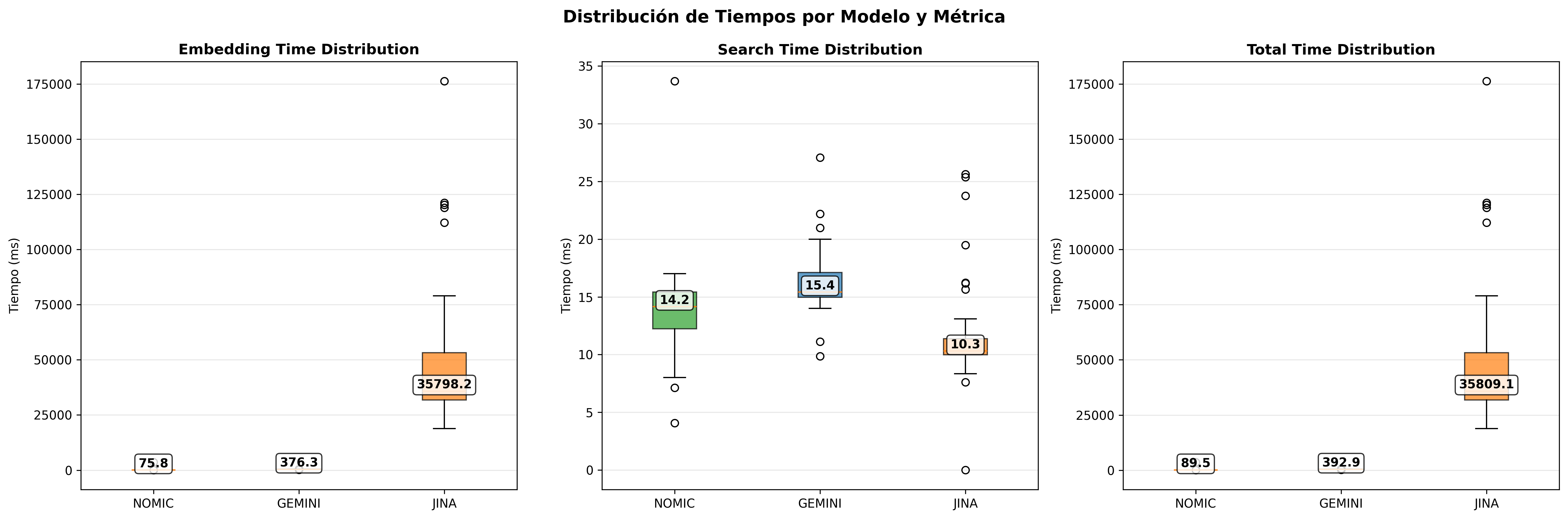
| Model | Embedding (ms) | Search (ms) | Evaluation |
|---|---|---|---|
| Gemini | 274.49 | 10.21 | Stable and reliable |
| Nomic Embed | 1958.16 | 9.06 | Very stable (local processing) |
| Jina | 4607.21 | 4.59 | Variable (free service) |
Operational Considerations: Jina, as a free experimental service, shows the greatest performance variability. Gemini maintains greater consistency thanks to its enterprise infrastructure. Nomic Embed demonstrates predictable stability due to its local nature.
Robustness Against Data Quality
An important finding from the analysis is that Nomic Embed requires very clean data for optimal performance, while Gemini and Jina demonstrate greater robustness with variable-quality data.
Unclean data affects all models by increasing:
- Token consumption and processing time
- Accelerated quota depletion (relevant for APIs)
- Computational overhead from poorly structured content
This consideration is important for model selection based on the quality of available input data.
Visual Analysis: Vector Space Structure
What Do the Visualizations Tell Us?
Our analysis included extensive visualizations that reveal important patterns:
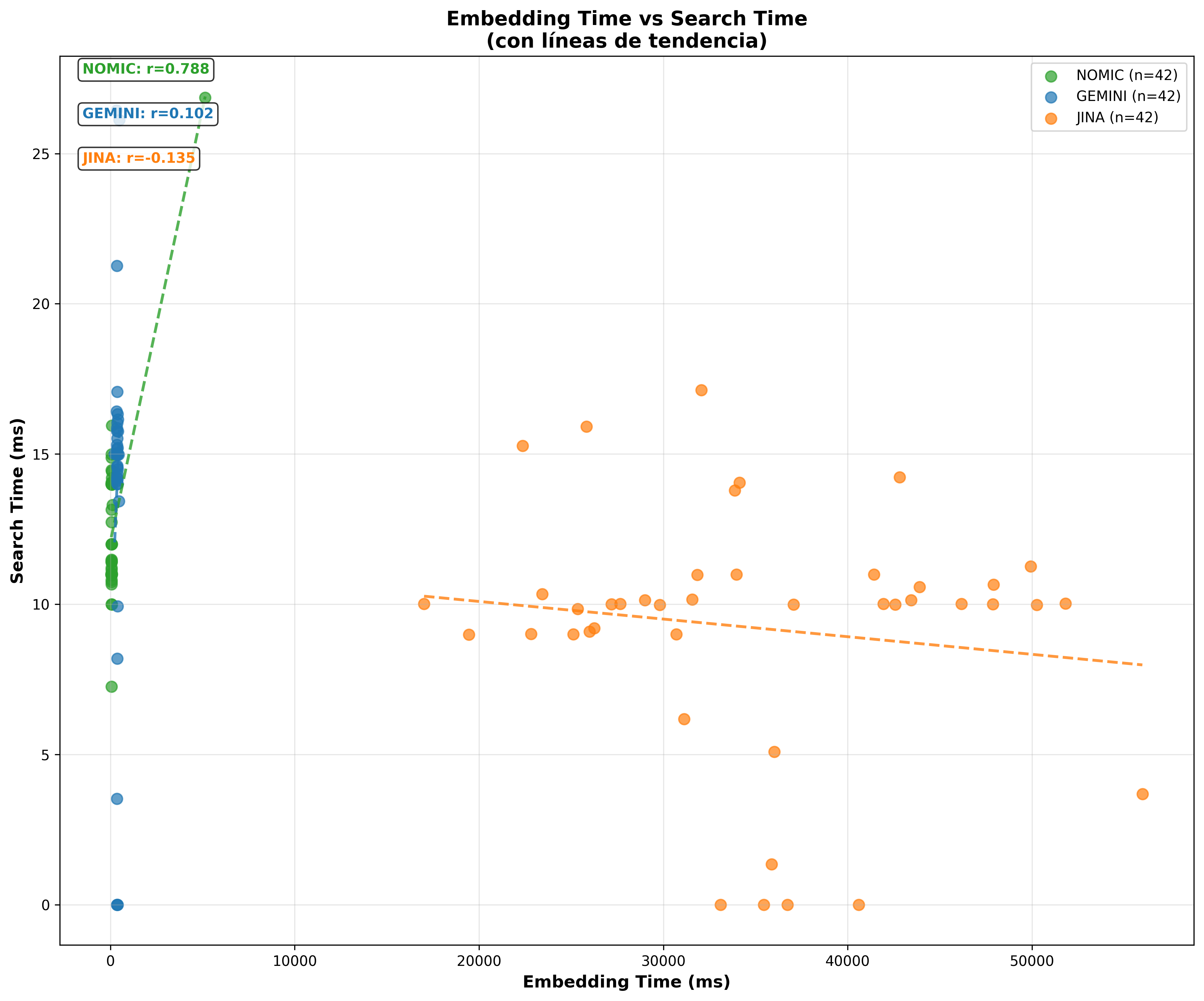
Performance Charts: Clearly show that vector search is always ultra-fast (less than 17ms), while embedding generation dominates the total time. It’s like discovering that in a relay race, all runners are equally fast, but some take much longer to receive the baton.
Performance Metrics
Speed Comparison (Performance Comparison)
Comparative charts reveal that Nomic Embed is consistently the fastest in total time, followed by Gemini, while Jina shows high variability due to free service limitations.
- Cosine Metric:
- L2 Metric:
Throughput Analysis (Velocity & Throughput Comparison)
These visualizations confirm Nomic Embed’s superiority in queries/sec and equivalent efficiency in chunks/sec across all models.
- Velocity Comparison Cosine:
- Velocity Comparison L2:
- Throughput Comparison Cosine:
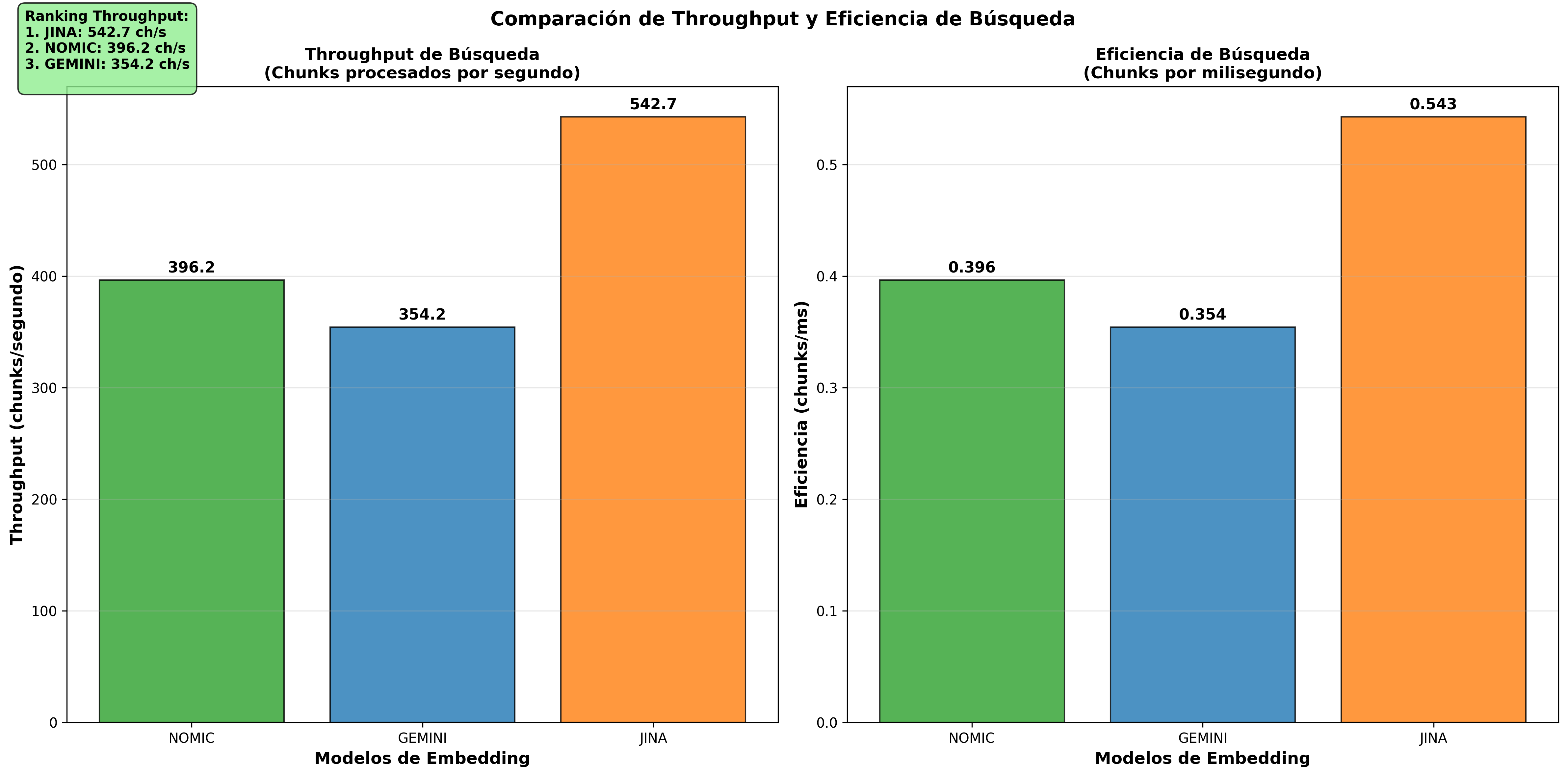
- Throughput Comparison L2:
Temporal Stability (Boxplots and Histograms)
Boxplots reveal that Gemini maintains enterprise-grade stability, Nomic Embed shows predictable local variations, and Jina displays greater dispersion due to free tier limitations.
- Performance Boxplots Cosine:
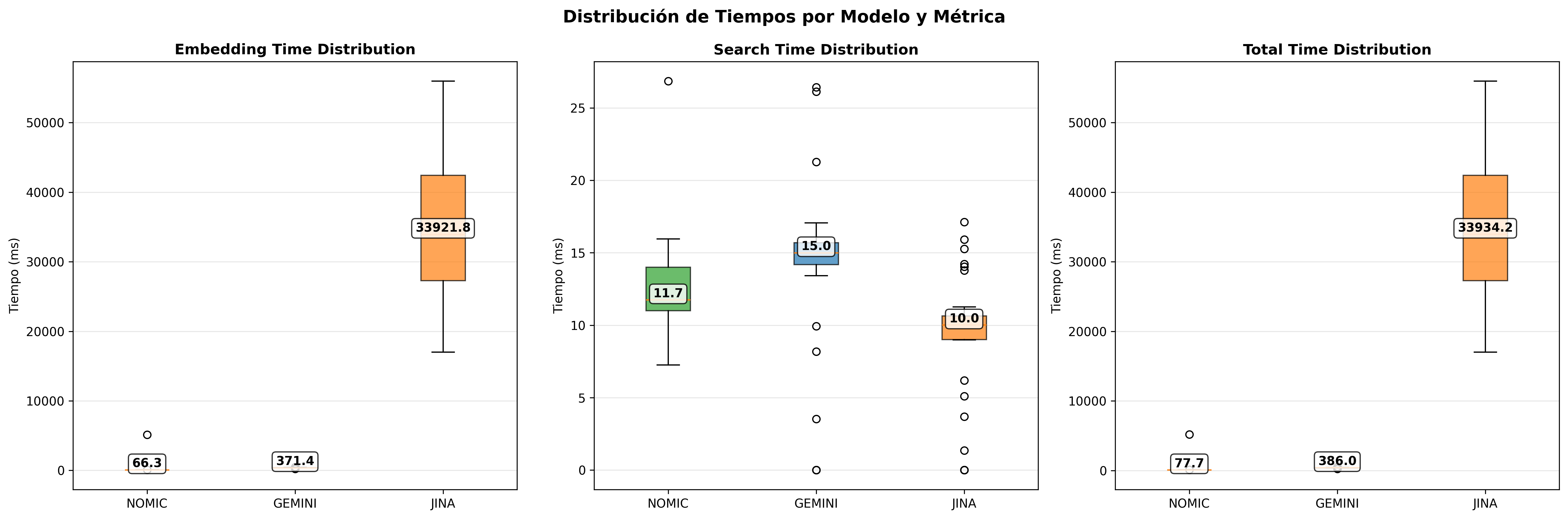
- Performance Boxplots L2:
- Timing Histograms Cosine:
- Timing Histograms L2:
- Timing Scatter Cosine:
 “
“ - Timing Scatter L2:
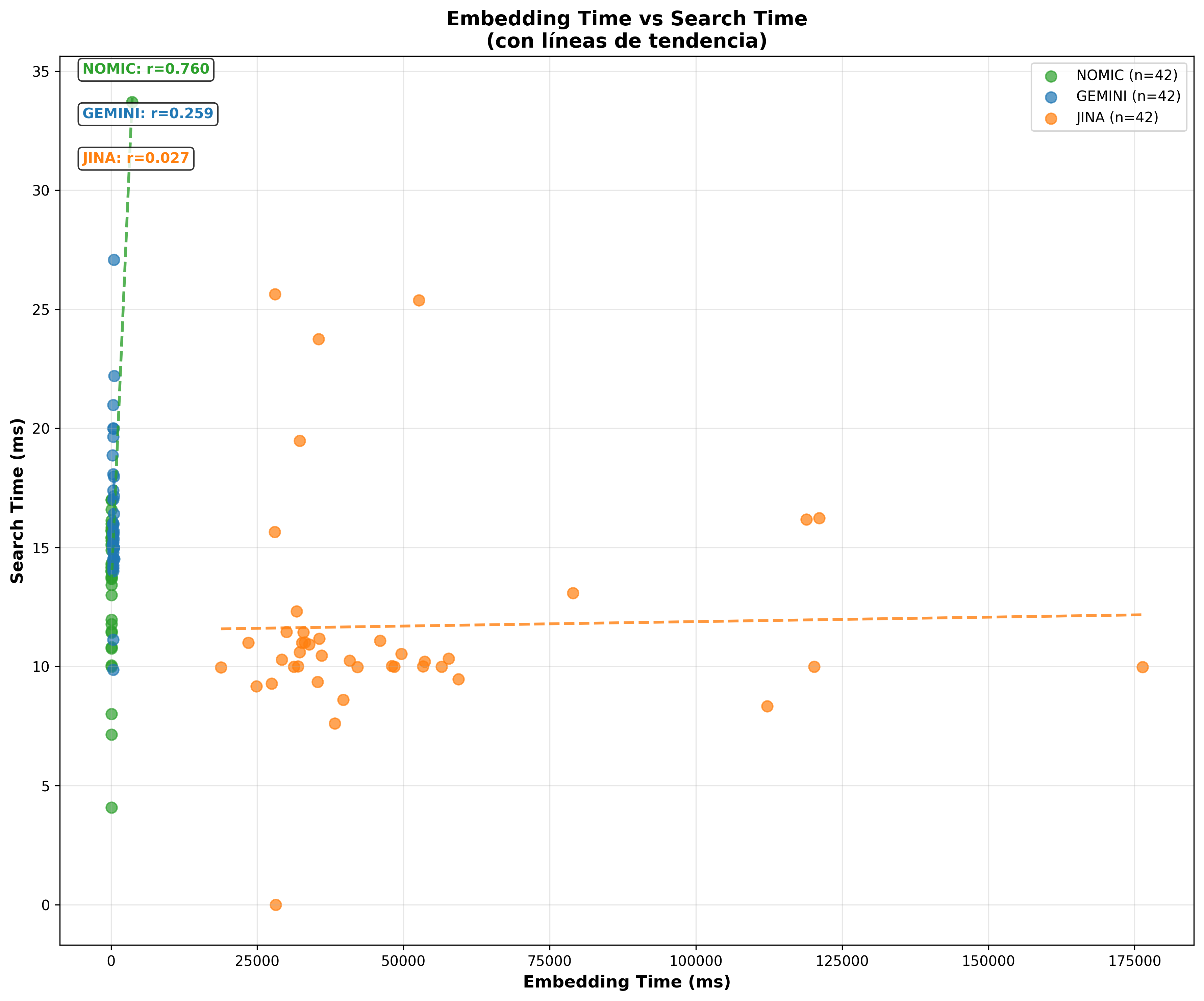 “
“
Vector Space Visualizations
t-SNE Projections: These 2D representations of the multidimensional vector space revealed a crucial finding: the spatial structure of embeddings is practically identical between L2 and Cosine. Documents cluster the same way, queries fall in the same places. Only the way of measuring distances changes.
Cluster Structure by Model
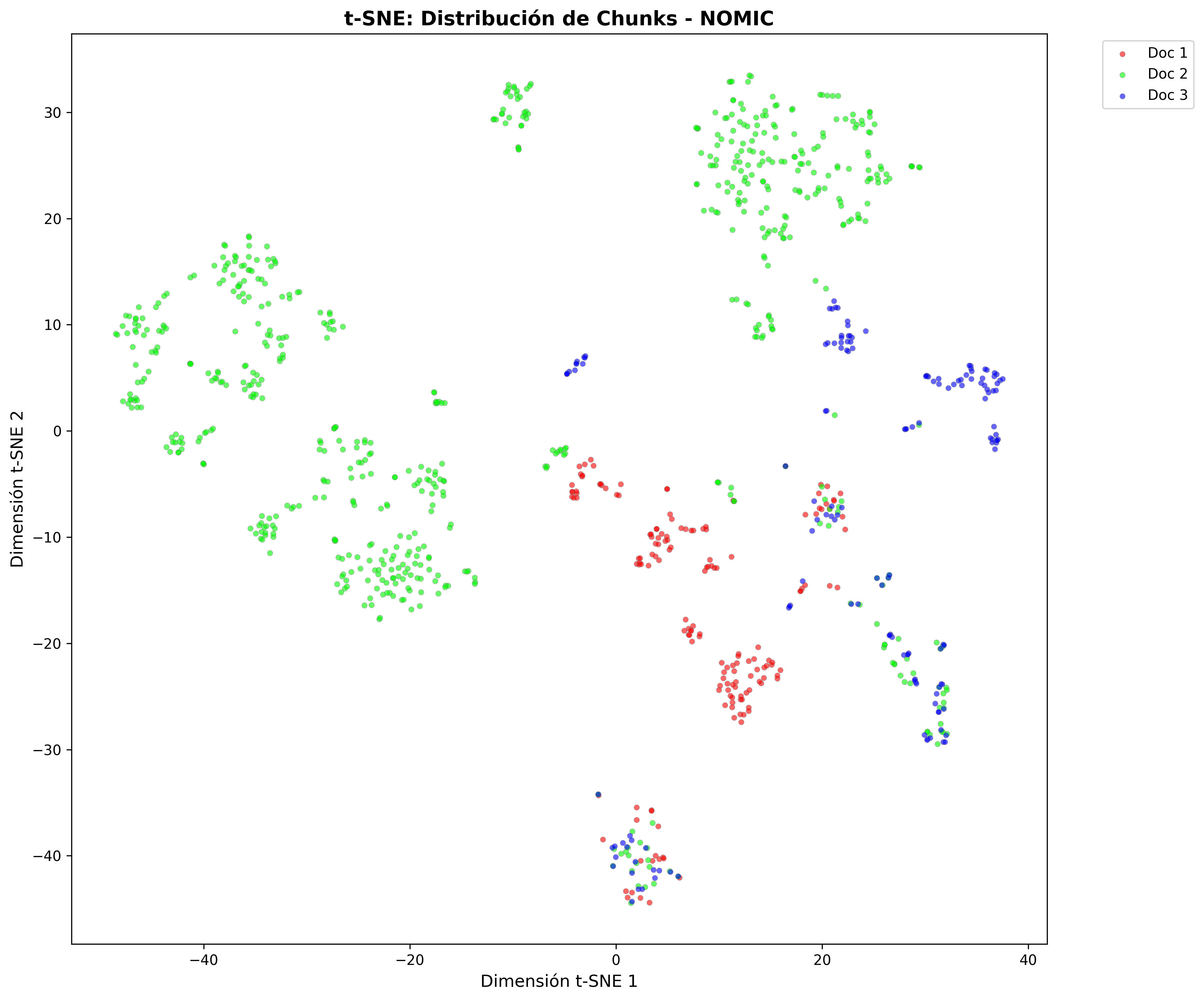
t-SNE projections show how each model organizes content in vector space:
- Gemini Chunks:
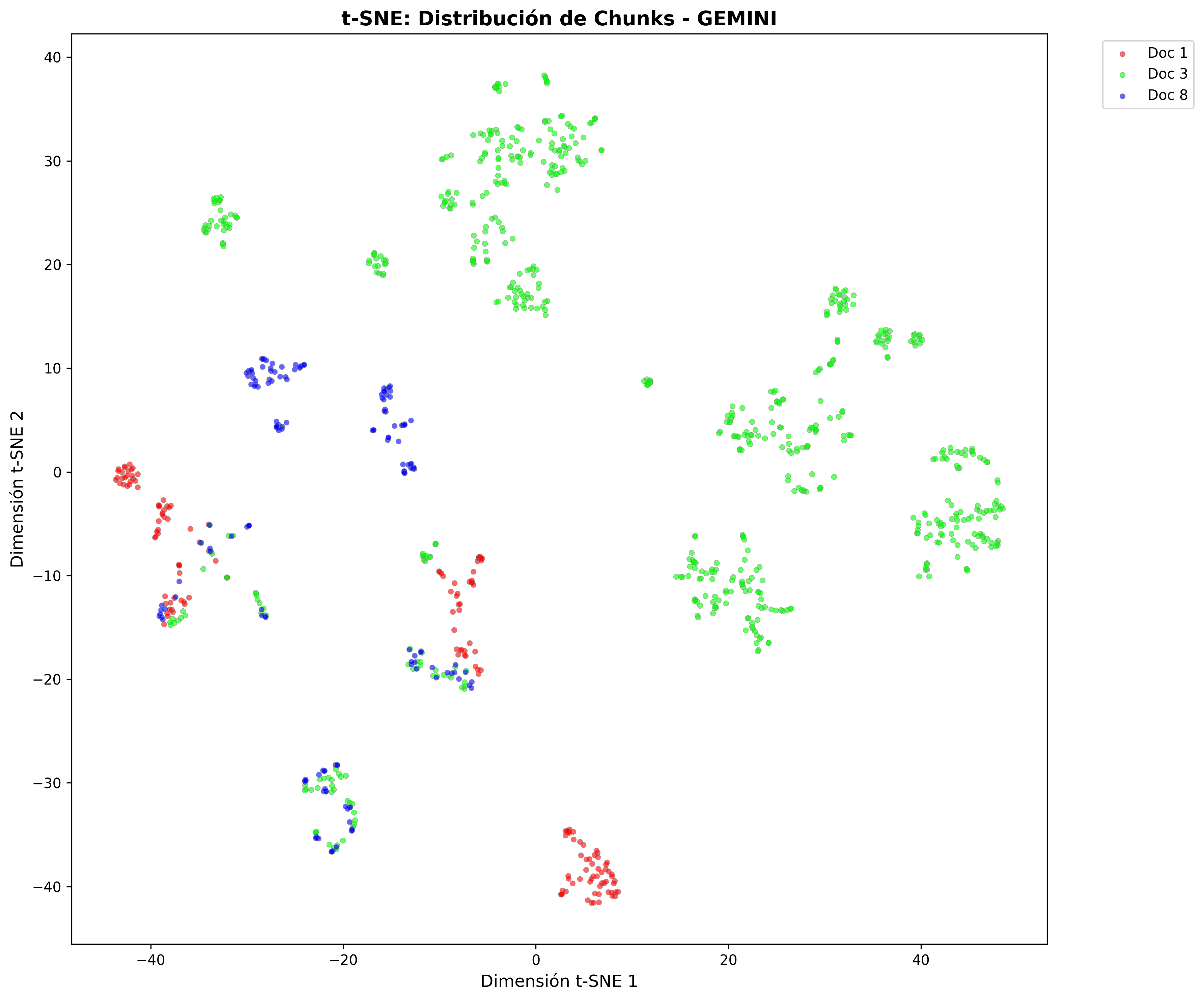
- Jina Chunks:
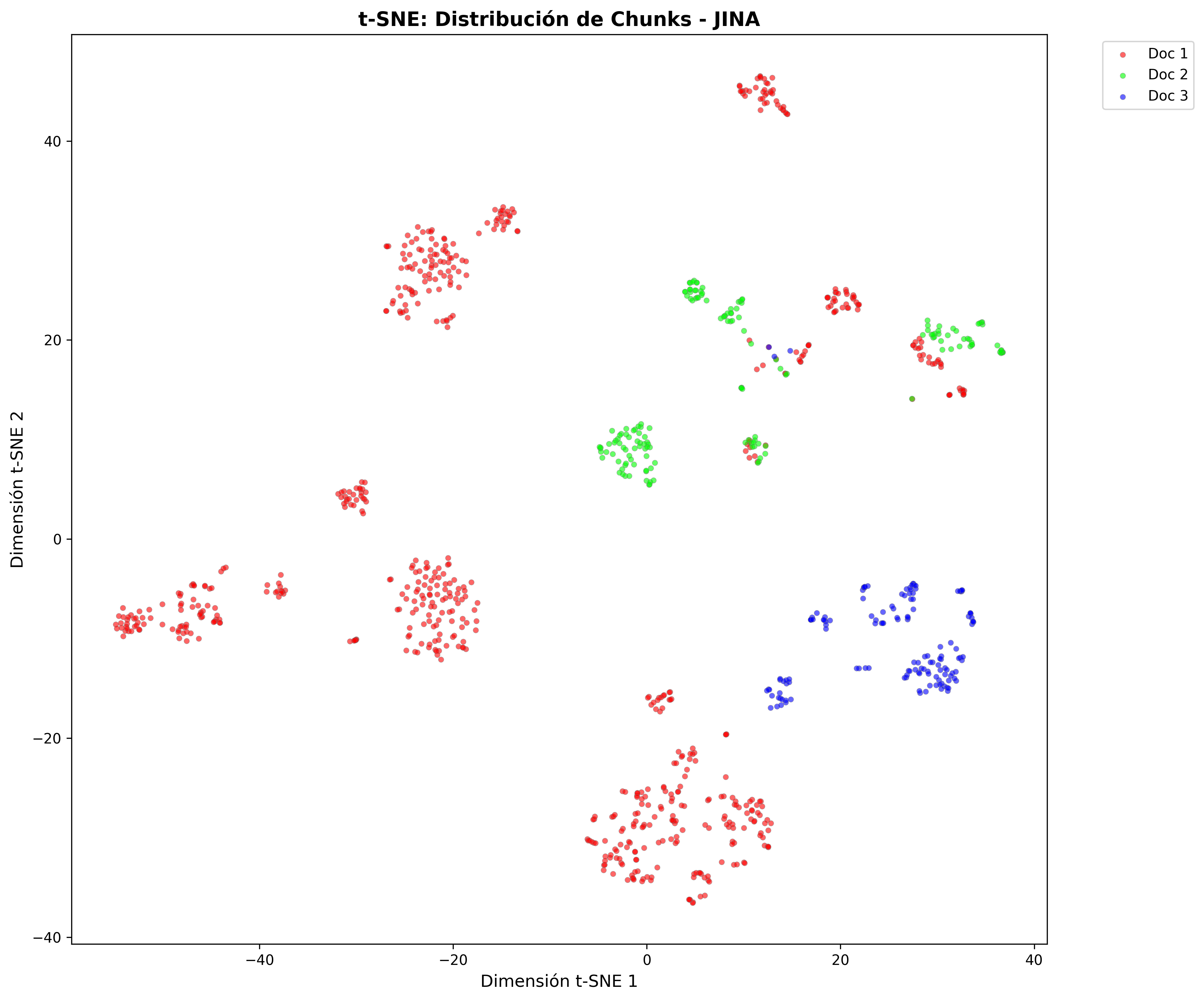
- Nomic Embed Chunks:
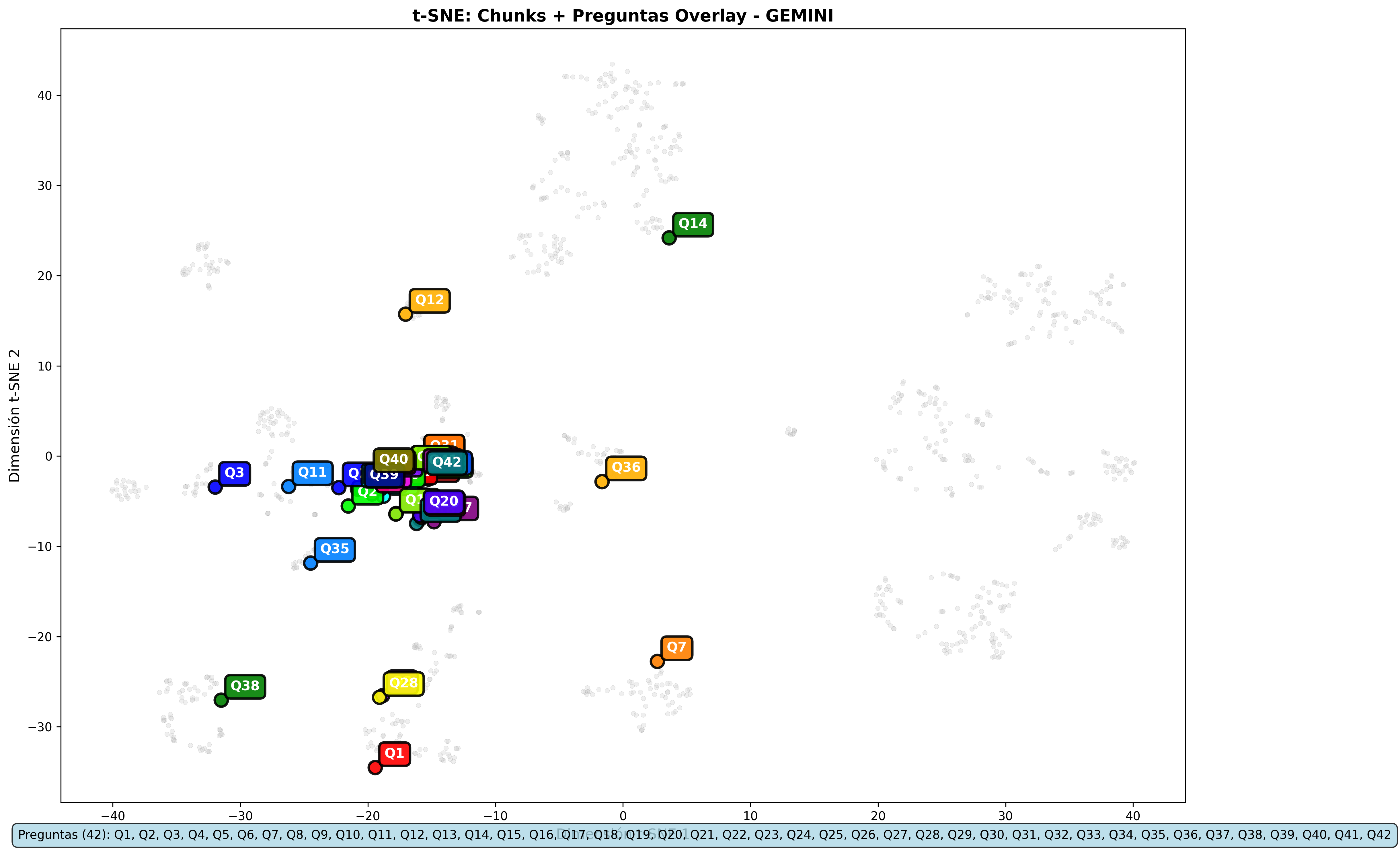
Overlay Analysis by Model and Metric
Overlays reveal how queries are positioned relative to content clusters:
Gemini Overlays:
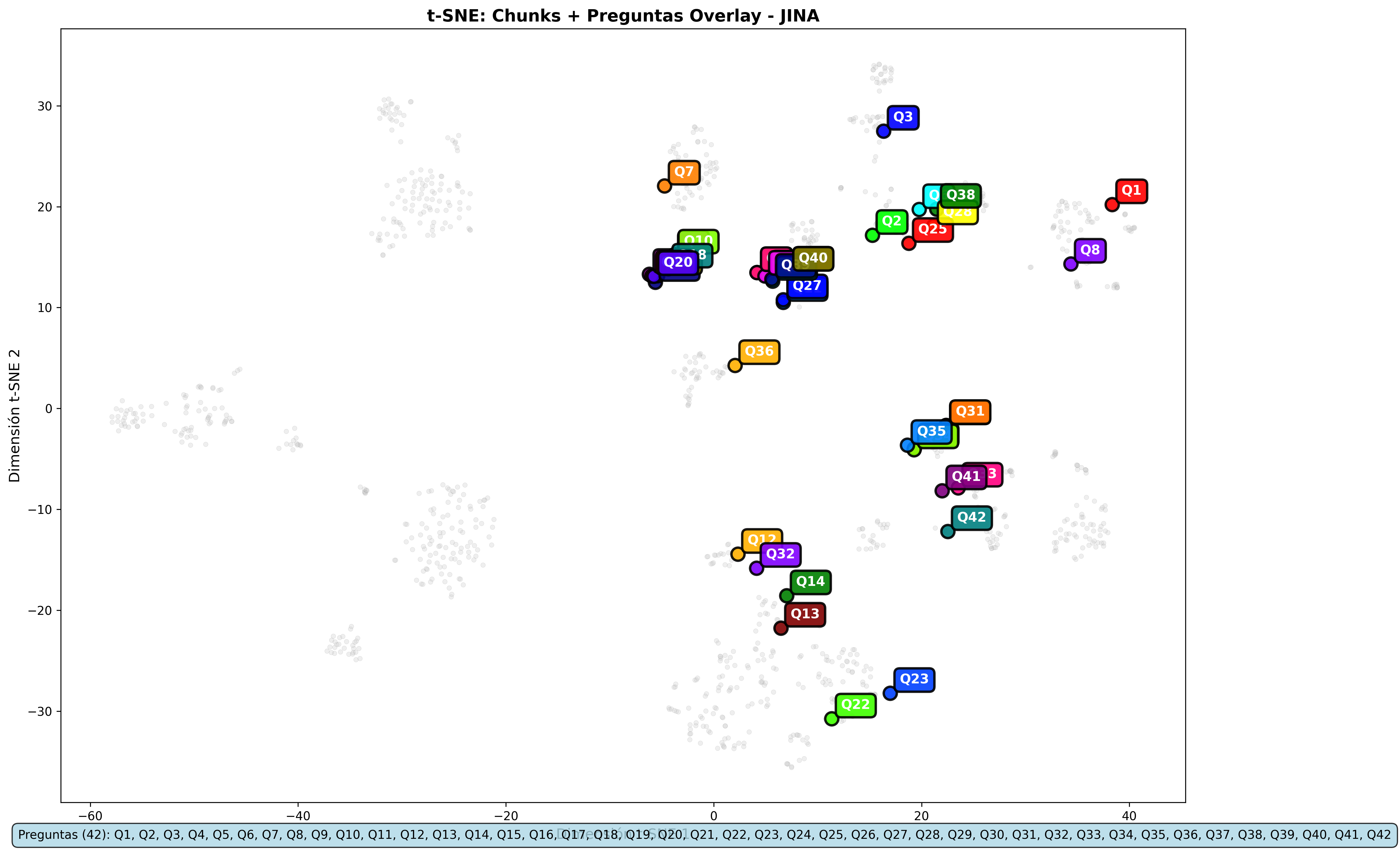
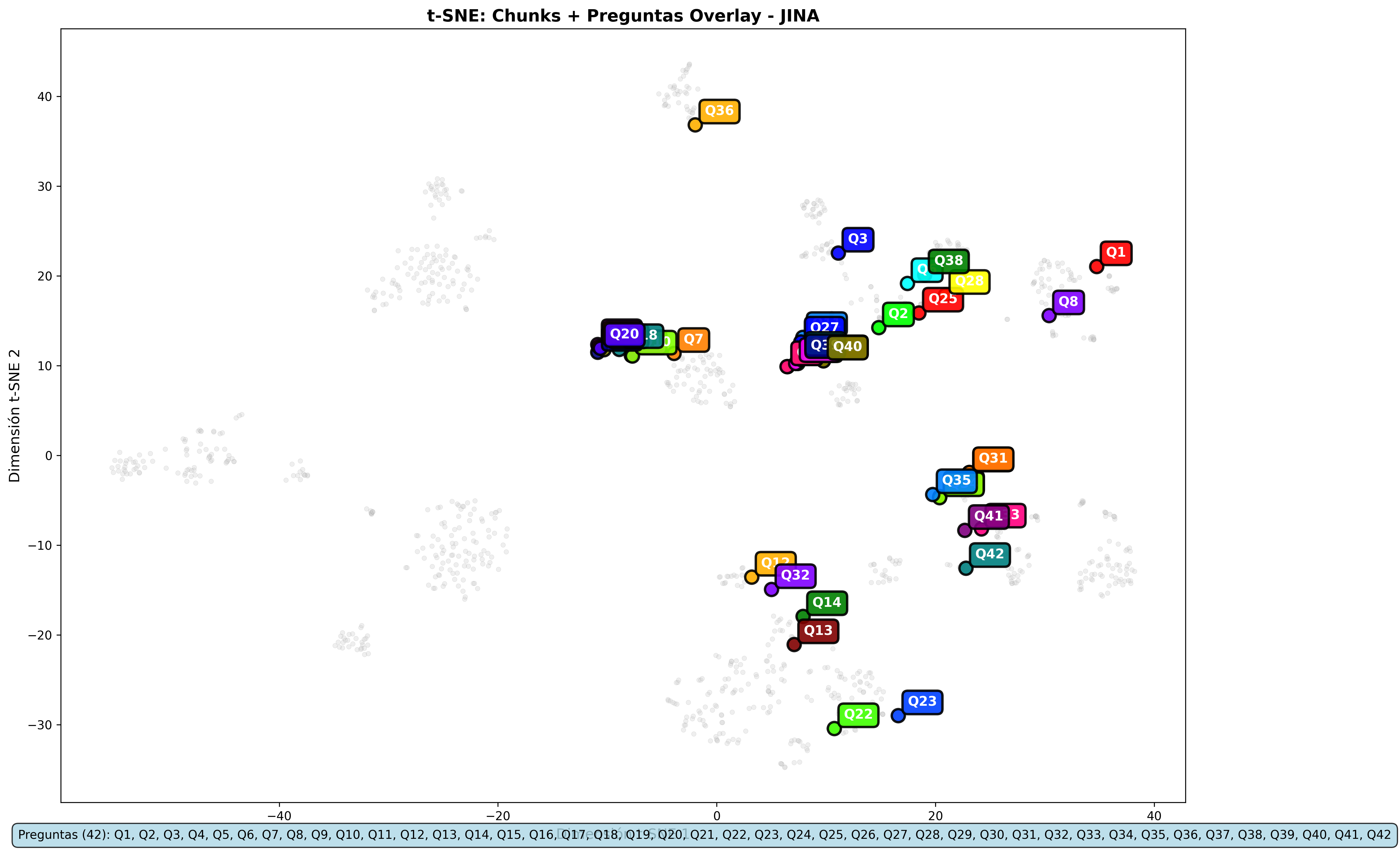
Jina Overlays:
- Cosine:
- L2:
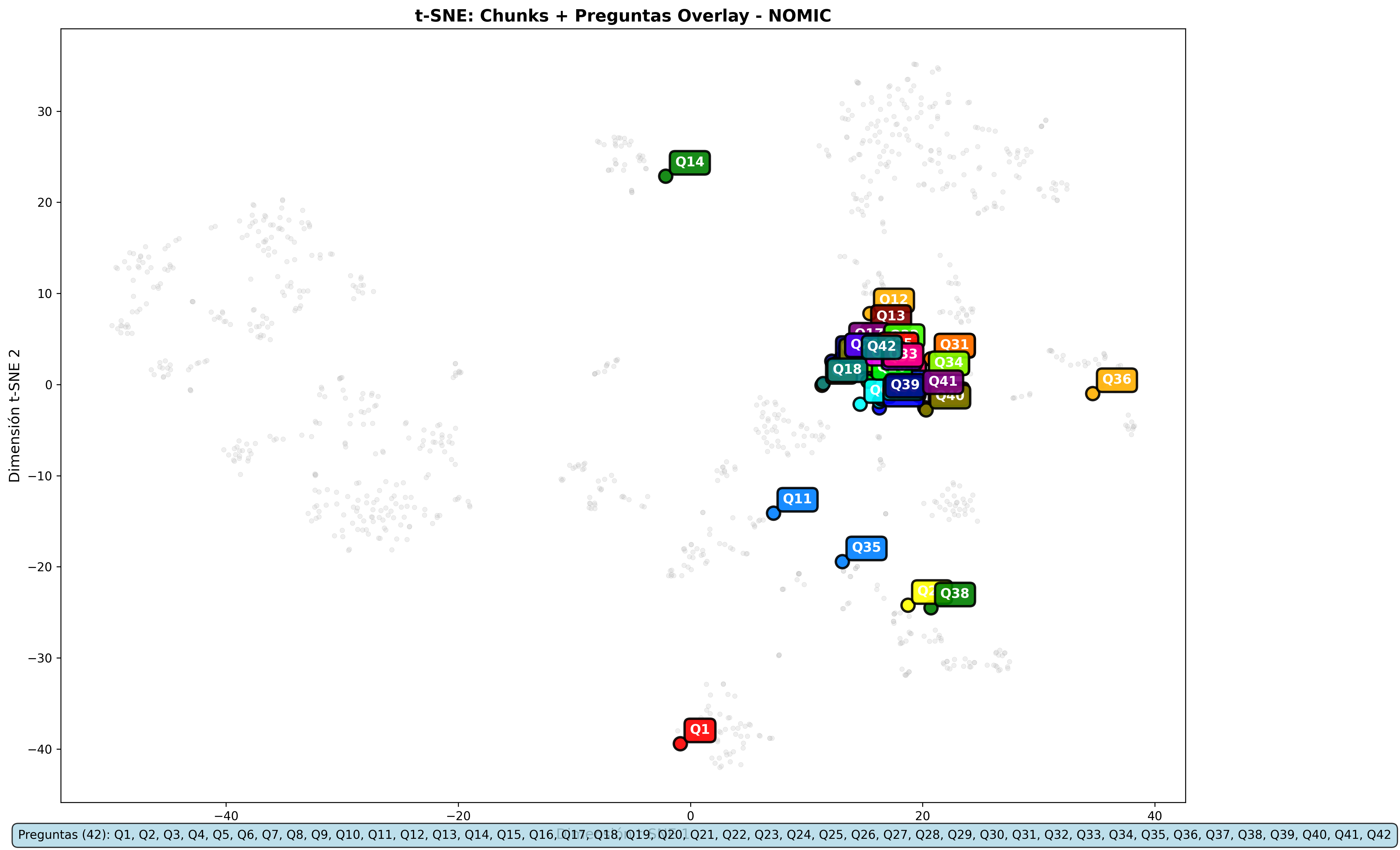
Nomic Embed Overlays:
Visualizations by Model:
- Gemini and Nomic Embed: Overlays are practically identical across metrics
- Jina: The only model that shows slight variations in overlays between metrics
The visualizations support the numerical conclusions: same content retrieval, differences only in the relevance scale.
Dimensionality Matters (But Not How You’d Expect)
A counterintuitive finding: Jina (1024D) is the fastest in searches, followed by Nomic Embed (768D) and finally Gemini (1536D). This challenges the intuition that more dimensions = more slowness. The reality is that algorithm optimization and implementation matter more than the raw number of dimensions.
Technical Details: Under the Hood
How We Convert Distances to Percentages
For L2 (Euclidean Distance):
relevancia = 100.0 / (1.0 + distancia / 10.0)This logarithmic formula compresses differences, making small distances translate to very high relevance scores.
For Cosine (Angular Similarity):
relevancia = similitud x 100.0A direct, linear conversion that exactly reflects angular similarity.
Operational Limits
API services present limitations that influence performance:
Gemini: 15 requests per minute, 1000 requests per day Jina: 10 million tokens, low-priority processing
These limitations partially explain the variability observed in response times and make local solutions like Nomic Embed offer predictability advantages.
Conclusions: When Theory Meets Reality
Final Comparative Evaluation
For speed and operational autonomy: Nomic Embed demonstrates clear superiority. No external dependencies, no API limits, with predictable performance. It represents a robust and autonomous solution for environments requiring constant availability.
For superior semantic quality: Gemini offers the best experience when precision is the priority. It provides high-quality embeddings with reliable enterprise infrastructure, though with usage limitations that require planning.
For quality-availability balance: Jina offers good performance when the service operates optimally. Useful as a specialized alternative, though with variability inherent to free services.
L2 vs Cosine: Comparative Analysis
After 42 queries and exhaustive analysis, the data shows that both metrics are functionally equivalent. The main differences:
- They retrieve exactly the same content
- Minimal speed differences (~2ms)
- They maintain identical spatial structure
- They differ only in scoring scales
The selection between them can be based on interpretation preferences: Cosine offers more conservative and directly interpretable scores, while L2 provides more optimistic scores due to its logarithmic transformation.
The Hybrid Strategy: Best of Both Worlds
For large projects like DOF-RAG, the optimal solution is a hybrid strategy:
- Gemini for critical documents where precision is fundamental
- Nomic Embed for bulk processing where we can accept a larger margin of error
- Jina as backup for special cases requiring a different perspective
Practical Recommendations
For complete operational autonomy: Nomic Embed is the optimal choice. The system will never depend on external APIs and will maintain predictable performance.
For maximum semantic quality: Gemini offers the best experience when precision is the priority, though it requires API limit management.
For experimentation with a limited budget: Jina provides a viable option for prototypes, though with variable response times.
On metric selection: Cosine for conservative and interpretable scores; L2 for optimistic scores. Both offer equivalent performance in content retrieval.
Final Reflections: The Future of Semantic Search
This analysis has taught us that in the world of embeddings, as in many aspects of technology, there is no single solution that is perfect for all cases. Choosing the right model depends on your specific priorities: autonomy or quality? Speed or precision? Cost or performance?
What is clear is that vector embeddings have democratized sophisticated semantic search. Models that a few years ago required million-dollar infrastructure can now run on a modest laptop. The future of intelligent search is not in the hands of a few tech giants, but within reach of anyone with enough curiosity to experiment.
And perhaps that is the most important lesson: in the AI era, technical knowledge remains power, but the real power lies in knowing how to apply these tools to solve real problems for real people.
This analysis is part of our DOF-RAG project to make Mexican governmental information more accessible. For more technical details, complete methodology, and access to the source code, check out our repository.
Analysis Details:
- Evaluation period: August 2025
- Queries analyzed: 42 representative questions
- Chunks processed: More than 1000 DOF document chunks
- Tools used: DuckDB, Python, native vector similarity methods
Comentarios